Key Takeaways
- Web scraping is shifting toward AI-driven, cloud-based, and compliance-aware methods, making the old selector-heavy and DIY approaches far less practical.
- Real browsers, managed infrastructure, and high-level APIs are becoming the standard because they offer greater reliability, fewer breakages, and stronger defenses against detection.
- Teams that prioritize data quality, automation, and responsible collection practices will be the ones who stay competitive, as the industry matures and expectations rise.
Introduction
Web scraping is going through a fundamental shift in 2026. What used to be a niche, highly technical task is becoming far more accessible thanks to AI and improved automation tools. Brittle selectors or one-off scripts no longer limit teams; they’re starting to describe the data they want, and AI figures out the rest. At the same time, sites are getting far better at spotting automated traffic, which pushes more teams toward real browsers and managed environments that handle the more complex parts for them. On top of that, stronger compliance expectations are shaping how pipelines are designed and how data is used. These three forces AI-native extraction, tougher anti-bot systems, and rising compliance pressure are setting up 2026 as the year scraping finally grows into a mature, reliable, and operational capability rather than a workaround or specialist skill.
What Web Scraping Looks Like in 2026
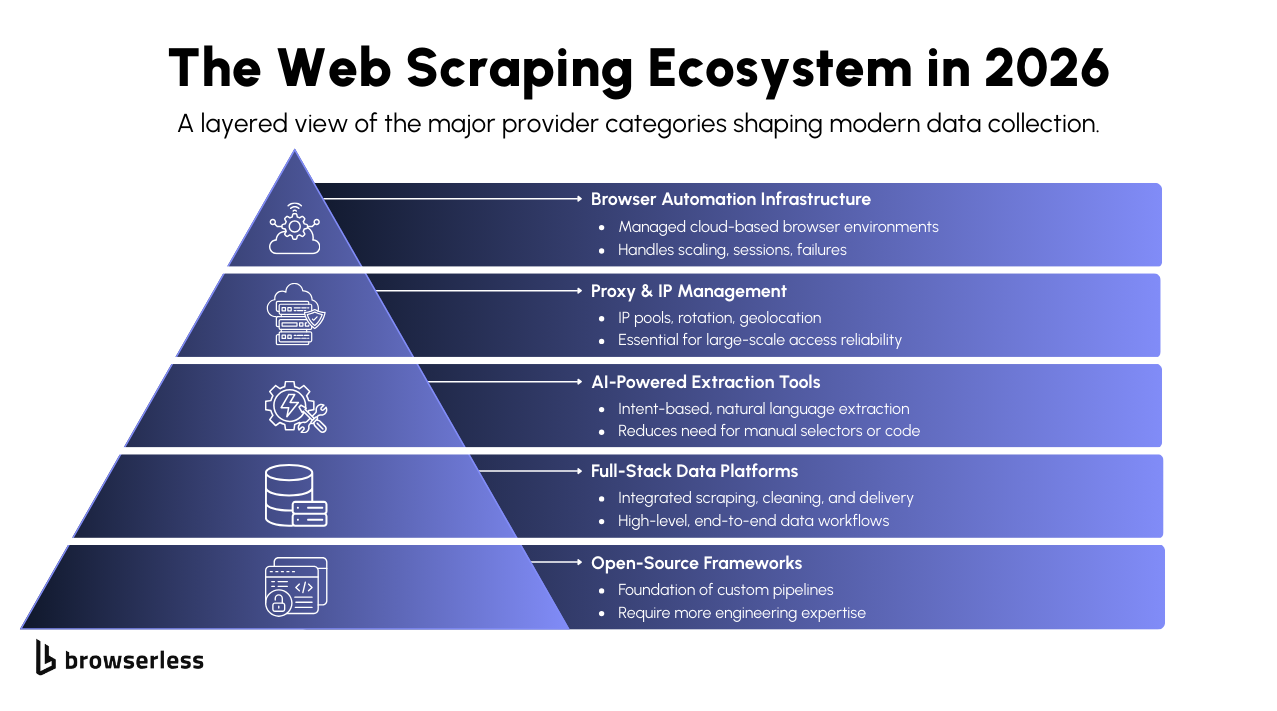
The ecosystem around scraping has grown quickly, and teams now have more options for collecting and processing web data. Providers are specializing, platforms are merging capabilities, and compliance expectations shape how pipelines are built. The result is a space that feels more mature and more aligned with how organizations want to operate in 2026.
More Tools and Providers Than Ever
The market spans several categories that support different pieces of the workflow. Browser automation infrastructure has become a common choice for teams seeking dependable, scalable environments without managing their own fleets. Proxy and IP services continue to play a significant role by offering managed networks that help maintain consistent access across regions and traffic patterns.
AI-powered extraction platforms are multiplying, giving teams a way to request data using high-level instructions rather than writing selectors. Full-stack data platforms bundle automation, proxies, extraction, and delivery into a single solution for teams that want less operational overhead. Open-source frameworks remain widely used when teams need flexibility and hands-on control.
Scraping Tools Are Starting to Merge Together
Providers are merging capabilities or absorbing smaller tools, giving customers more complete solutions instead of scattered point products. This trend is driven by a desire for simpler stacks and fewer systems to maintain.
At the same time, higher-level abstractions are replacing manual steps; teams are spending less time building low-level automation and more time describing the outcomes they want. This reflects how AI-driven extraction and managed infrastructure have changed expectations for what a modern scraping workflow looks like.
Compliance Now Shapes How Scraping Is Built
Compliance now plays a direct role in the design of scraping workflows. Regulations are being enforced more consistently, and organizations are treating responsible data collection as a requirement from the start rather than something evaluated later.
The focus has shifted to asking whether data should be collected and how to handle it responsibly once it is collected. This shift is pushing teams to be more deliberate about policies, data minimization, storage, and transparency.
5 Big Tech Shifts Changing Web Scraping in 2026
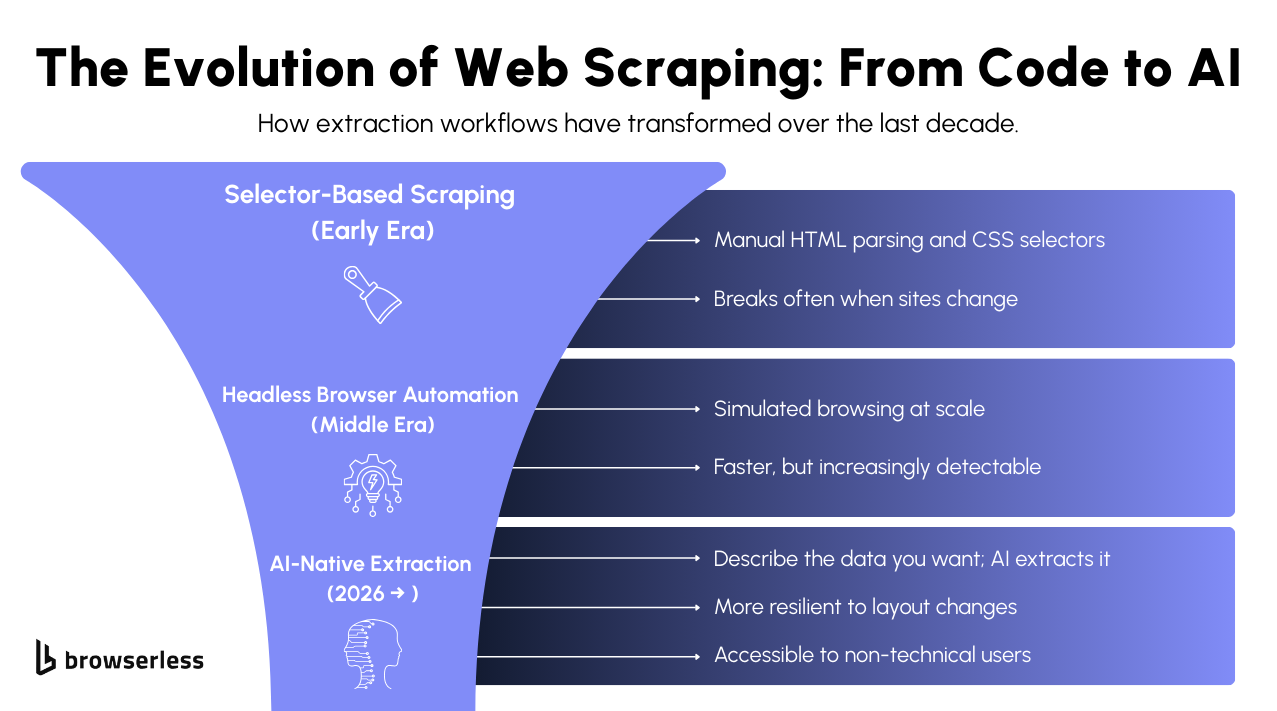
The technical side of scraping is evolving quickly, and 2026 is shaping up to be a year where the biggest shifts become part of everyday workflows. AI is changing how teams interact with websites, anti-bot systems are raising the bar, and cloud-native automation is becoming the norm. These trends influence not only how data is collected but also how teams think about reliability, scale, and who can participate in building pipelines.
1. AI Becomes the Main Way People Extract Data
AI-native extraction is reshaping how teams interact with web data. Instead of writing selectors or tracking DOM details, users describe the data they need and let models interpret the structure.
This intent-based approach makes extraction more flexible, especially when websites update their layout. This is the most impactful shift as AI reduces the need for specialized knowledge of scraping.
Because the interface is natural language, non-technical users can now build pipelines that previously required engineering support. These AI-driven extractors adapt better to page changes, improving long-term reliability compared to static code.
2. Real Browsers Beat Headless for Reliability
Modern anti-bot systems have become very good at spotting headless browser patterns, which has pushed teams toward using full browser instances instead. This shift is why many teams now rely on managed cloud browsers; they offer better success rates without requiring organizations to maintain fleets, handle sessions, or stitch proxies together manually.
3. Anti-Bot Defenses Get Much Tougher
Anti-bot systems now use multiple detection vectors, behavioral analysis, advanced fingerprinting, and machine learning models. As detection becomes more aggressive, the operational lift increases. Teams often turn to managed services that specialize in evasion, browser realism, and correct session handling. This reduces the need to maintain custom bypass strategies internally and helps teams focus on data outcomes instead of defensive tactics.
4. Scraping Moves Fully Into the Cloud
Scraping workloads are moving to cloud-native environments where scaling is on demand and failure handling is built into the platform. This model allows teams to adjust capacity based on job volume. Browser fleets, retries, and session management become cloud-managed tasks instead of in-house engineering responsibilities. As a result, scraping pipelines become easier to maintain and more adaptable to changing workloads.
5. Scraping Now Includes Full Page Interactions
Scraping is no longer limited to collecting static content from pages. Teams increasingly automate multi-step workflows that include logging in, filling forms, navigating menus, and interacting with dynamic elements.
This evolution supports more complex data requirements and enables pipelines that behave more like human operators. As AI models improve, these workflows become more intuitive to describe, making automation feel more like defining a goal than writing procedural steps.
Top 4 Challenges Teams Face With Web Scraping

Scraping has become more capable, but several challenges still make day-to-day operations difficult. Websites change often, detection systems keep advancing, and infrastructure demands grow as workloads scale. Teams also face rising expectations around responsible data practices, which influence how pipelines are built and maintained.
1. Dynamic Sites Make Consistent Data Hard
Websites frequently personalize content, run A/B tests, and dynamically load elements. These variations make it harder to gather consistent data across sessions, since the structure and content may shift from one request to the next. This creates a need for more advanced validation so teams can confirm whether differences are expected behavior or true extraction failures.
Because layouts often evolve, scrapers break more easily. Even small UI changes can affect parsing logic, increasing the ongoing work required to keep pipelines stable.
2. Detection Systems Block Scrapers More Often
Modern anti-bot systems use multiple detection signals at once: behavioral patterns, fingerprinting, network characteristics, and device-level checks. Basic tactics like rotating user agents or switching IPs no longer get meaningful results.
As these systems tighten their defenses, success rates drop unless teams use more sophisticated browser automation or environments designed to mimic real user behavior. This pushes many organizations toward managed platforms that can adapt quickly as detection methods evolve.
3. Running Scraping Systems Yourself Is Expensive
Running your own browser fleets, handling proxy rotation, storing sessions, and coordinating retries can take a lot of engineering time. Larger data pipelines magnify this workload, especially when pipelines must react to site changes or detection events.
DIY setups often entail high maintenance costs because each scraper requires monitoring, updates, and failover logic. This is why more teams move to managed browser infrastructure, offloading scaling, reliability, and operational management, reducing the constant upkeep.
4. Compliance Adds New Responsibilities
Expectations around ethical and compliant data collection have increased. Teams now think carefully about whether the data they collect aligns with privacy requirements and website policies.
Governance is becoming part of pipeline design rather than an afterthought. Many organizations are adopting practices such as data minimization, clearer internal policies, and stricter rules for handling personal information to reduce risk and operate more transparently.
Emerging Approaches & Best Practices for 2026
Teams are modernizing their scraping setups to handle rising complexity, stricter detection systems, and higher expectations for responsible data use. Many of the newer practices focus on reducing maintenance, improving reliability, and shifting effort away from low-level automation. These approaches set a more sustainable direction for scaling operations through 2026.
More Teams Are Using Managed Cloud Browsers
More teams are using cloud-managed browser environments to avoid the overhead of maintaining their own fleets. These platforms handle scaling, session management, and resource allocation, which helps teams avoid infrastructure bottlenecks. They also give developers a more dependable foundation for complex or high-volume workloads.
Automatic retries, session continuity, and built-in fault handling reduce the day-to-day work required to keep scrapers stable. With these features handled by the platform, teams can spend more time focusing on the data they want rather than recovering from failures or browser breakdowns.
High-Level APIs Replace Low-Level Scripts
High-level APIs are becoming more common as teams move away from writing navigational code. Instead of scripting selectors, clicks, and waits, users describe the desired output, and the platform handles navigation, extraction, and interpretation. This makes workflows more accessible to non-technical users and reduces the chance of breakage when sites change.
Built-in validation and error handling add stability. These APIs can interpret layout shifts, retry failed steps, and deliver structured results without requiring custom logic. This creates a smoother experience for teams that want reliable outcomes without deep scraper maintenance.
Pipelines Are Moving to Microservices
Teams running larger operations are adopting microservices patterns to separate fetching, parsing, cleaning, and storage. By isolating these components, pipelines become easier to scale and troubleshoot. Each service can evolve independently, reducing downtime and allowing teams to improve parts of the system without impacting the entire pipeline.
This modular structure supports more predictable performance. When a parsing service needs more CPU or a fetcher needs more concurrency, teams can scale just that component rather than the entire pipeline. As scraping workloads grow, this flexibility becomes increasingly valuable.
AI Helps Catch Data Errors Early
AI-driven validation tools are helping teams catch inconsistencies before data reaches downstream systems. Models can flag anomalies, detect missing fields, and assign confidence scores to extracted values. This gives teams better insight into whether a page change or rendering issue has affected the output.
These feedback loops strengthen long-term data reliability. Instead of discovering problems after analysis, teams get early signals and can correct extraction logic or adjust workflows before issues spread.
Compliance Becomes a Built-In Step
Compliance expectations are shaping how pipelines are built from the start. Teams increasingly adopt minimal-collection strategies, gather only what is required, and design systems that respect website rules and regional privacy standards. This reduces legal risk exposure and encourages long-term stability.
Practices like anonymization, transparent operational policies, thoughtful rate behavior, and careful storage controls are becoming standard. These measures help organizations run data operations that align with both regulatory expectations and internal governance goals.
What’s Ahead: Predictions for 2026
2026 will bring meaningful shifts in how teams design and operate scraping workflows. AI-driven extraction will mature quickly, managed infrastructure will grow, and compliance will have a more substantial influence on technical decisions. These changes reflect the direction already visible in the market and will shape how teams plan their data strategies.
What’s Changing Right Now
AI-native extractors will gain broader adoption as teams look for more stable, adaptable ways to gather data without constant maintenance. As these tools become more reliable, more organizations will rely on natural-language–driven extraction instead of brittle selectors. The market will also continue consolidating as platforms expand into full-stack solutions, giving teams fewer fragmented tools to piece together.
Compliance expectations will rise as regulators increase enforcement and organizations sharpen their internal policies. This will influence how teams design pipelines, select vendors, and decide what data to collect.
What’s Likely Coming Next
Managed services are likely to surpass DIY scraping setups as teams reduce their reliance on internally maintained infrastructure. Session handling, browser scaling, and adaptive behavior will be managed by cloud platforms specializing in high-reliability environments. Intent-driven agents will become more common, taking on multi-step workflows such as navigation, form handling, and dynamic interactions.
High-level APIs will increasingly replace operational code, allowing developers and non-technical users to describe outcomes rather than write low-level automation. This shift will make scraping more accessible and reduce long-term maintenance.
What Could Change Faster Than Expected
If AI advances faster than expected, autonomous agents capable of interpreting goals and completing complex workflows could arrive sooner. These agents would streamline tasks that currently require multiple layers of logic or human oversight.
If anti-bot systems escalate more aggressively, reliance on real browsers will grow quickly, pushing teams toward cloud-managed environments that better match human traffic patterns.
And if regulatory tightening accelerates, organizations may move toward more conservative pipelines that emphasize governance, minimal data collection, and transparent operational policies.
Conclusion
2026 marks a major shift toward AI-first, cloud-native, and compliance-aware scraping, and teams that adapt early will be far better equipped to meet the demands of modern data collection. Organizations that embrace higher-level abstraction, invest in data quality, and rely on reliable automation will move faster and operate with far less friction. The future of scraping is shaped by reliability, responsibility, and resilience, and teams that lean into these principles will see the most substantial long-term gains. If you’re ready to modernize your scraping workflow or want to try managed browser automation firsthand, you can sign up for a free trial with Browserless and explore what the new generation of scraping looks like.
FAQs
What is changing about web scraping in 2026?
Web scraping is becoming more AI-driven and cloud-native. Teams are moving away from fragile scripts and toward tools that understand natural language, automate tasks, and adapt to site changes without constant maintenance.
Why are real browsers replacing headless browsers?
Real browsers behave more like human users, making them harder for anti-bot systems to detect. Headless browsers get flagged more often, which lowers success rates. Real browsers in the cloud give better reliability with less manual setup.
What makes anti-bot systems harder to bypass now?
Modern detection systems analyze many signals at once behavior, fingerprints, network characteristics, and device patterns. Simple tricks like rotating user agents or IPs no longer work, so teams need managed browsers or advanced automation tools to stay reliable.
Why are companies moving toward managed scraping infrastructure?
Running scraping systems yourself requires maintaining browser fleets, proxies, retries, and session handling. Managed platforms take care of all that so teams can focus on the data they need rather than fixing breakages or scaling servers.
How is compliance changing web scraping?
Organizations are expected to collect only what they need, respect website rules, and protect personal data. Compliance now shapes pipeline design from the start, leading teams to adopt safer, more transparent scraping practices.