Tl;dr
BrowserQL is a big step for Browserless so there’s a lot to cover, but here’s the key points:
- It’s based around our own browser query languageThis directly controls the browser via Chrome Devtools ProtocolIt avoids all the fingerprints left by libraries such as Puppeteer/PlaywrightBrowserQL gets past almost all detectors out the box, and we can help with ones it can’tIt includes actions and conditions, such as clicking and if statementsThe language makes assumptions, such as if you mention a selector it will wait for and scroll to itAlpha tests report that automations requiring hundreds of lines of Puppeteer code take a couple dozen with BrowserQLThe language is based on GraphQL and can be run with a cURL command
- This directly controls the browser via Chrome Devtools Protocol
- It avoids all the fingerprints left by libraries such as Puppeteer/Playwright
- BrowserQL gets past almost all detectors out the box, and we can help with ones it can’t
- It includes actions and conditions, such as clicking and if statements
- The language makes assumptions, such as if you mention a selector it will wait for and scroll to it
- Alpha tests report that automations requiring hundreds of lines of Puppeteer code take a couple dozen with BrowserQL
- The language is based on GraphQL and can be run with a cURL command
- BrowserQL comes with a dedicated IDE built for scraping and automationtYou get a live view of the browsers in production for easier debuggingThis includes a Chrome debugger you can toggle on and offThere are inbuilt docs, so you don’t have to keep switching focus
- You get a live view of the browsers in production for easier debugging
- This includes a Chrome debugger you can toggle on and off
- There are inbuilt docs, so you don’t have to keep switching focus
- Gets past IP and hardware fingerprintingComes with inbuilt ISP and residential proxiesRuns on our cloud which includes real hardware for device fingerprinting
- Comes with inbuilt ISP and residential proxies
- Runs on our cloud which includes real hardware for device fingerprinting
- Can generate endpoints for reconnects, other libraries or AI agentsReconnect to a session to run multiple automations in one browser instanceUse the unlocked endpoint for Puppeteer, Playwright or AI agents
- Reconnect to a session to run multiple automations in one browser instance
- Use the unlocked endpoint for Puppeteer, Playwright or AI agents
Put together, it looks something like this:
To test it out, start a trial or log into your account page, and hit the download button. The BQL editor is available to run on Mac, Linux and Windows.
Or, keep reading for more details.
Bypass bot detectors such as Cloudflare and DataDome, through humanization and minimal fingerprints
Using a library such as Puppeteer or Playwright with some stealth settings used to be a sure way to get past bot detectors. But, things have escalated, and now that’s rarely enough.
Avoiding all library fingerprints
These libraries are designed for completion, not stealth or efficiency. For example, they interact with every single page, iframe and service worker by default. These types of behaviors are good for E2E testing but are easy for bot detectors to spot when scraping, so you end up having to fight against the libraries themselves to hide their fingerprints.
BrowserQL takes a more minimal approach. We only make the fewest possible interactions, directly via Chrome Devtools Protocol (CDP).
This has the fun side effect that it’s also typically much faster than those other libraries. This efficiency together with our optimized browser pool means you can often retrieve HTML in a few hundred milliseconds.
Humanized interactions by default
To further hide signs of automation, we have humanization built into all the code. For example, let’s say you want to enter a string into a form field. BrowserQL will automatically:
- Wait until the form field is loaded
- Scroll down so it’s visible on the screen
- Move the mouse over to the field
- Click somewhere within the element
- Enter the text at a realistic speed
- Occasionally make and fix typos
- Only move on to further fields and clicks once it’s finished typing
This is all done out of the box, without you having to code up any of the actions. You can even watch it happening in the live view.
Run on hardware for device fingerprinting
We have found that some bot detectors are now looking at if the device includes a GPU and other signs that it is on a piece of “real” hardware.
Unlike user agents, this isn’t something you can fake. With BrowserQL, the browsers can run on real consumer hardware when necessary to unlock those sites. This is currently only available for enterprise users, but we plan to expand it to all plans.
Our team will help unblock sites that don’t work immediately
We’re very confident in BrowerQL’s ability to unblock sites. But, the landscape is constantly shifting.
If you come across a site where you are still bot blocked, just send a note to our support team. We would be happy to help find a way through, plus it helps us stay on top of new developments.
Minimal lines of code required
We wrote BrowserQL with various assumptions, as we expect it to primarily be used for scraping and other automations.
You don’t have to write any boilerplate code for common actions like scrolling, waiting or clicking. We have pre-configured components and libraries to handle all of those details in the background.
GraphQL-based language
The language is based on GraphQL, so you end up writing a set of queries/actions with a response for each, along with possible arguments.
# Name your script, give it a URL and define a wait condition if wanted
mutation exampleScript {
goto(url: "https://www.example.com/",
waitUntil: firstContentfulPaint) {
status
time
}
# Name each function and choose an action such as typing,
# clicking or querying a selector, then define a response.
itemPrice: text(
selector: "[id='product-price']"){
text
}
# We handle details such as waiting for the element, scrolling so
# it's visible, mousing over to and clicking it, typing
# organically and interacting with iframes.
customFunction: type(
selector: "form [data-testid='login-input-email']"
text: "test@browserless.io") {
selector
}
Our alpha testers regularly reported having to write 10x less code when moving automation scripts over from other libraries.
Having to always define a response might feel odd for actions such as clicking, but it comes in very handy when you’re trying to debug an automation.
Includes if conditions
You can include conditional statements directly in your queries. Maybe you want to check for a cookie banner or form field before trying to interact with it. With BrowserQL you can easily add that into the request.
Export to a cURL command or a JSON object
Once you’ve finished writing your automation, you can export it to run as a cURL command or with a JSON object. That makes it compatible with any language or tech stack.
curl --request POST --url 'https://chrome.browserless.io/bql?token=KEY&proxy=residential' --header 'Content-Type: application/json' \
--data '{
"query": "mutation Amazon { goto( url: \"https://www.example.com/" ) { status time } text(selector: \"id='product-price'\") {text} }",
"variables": {},
"operationName": "exportExample"
}'
The export will include any variables you’ve defined such as your API key, along with settings such as proxy details.
Here's the full flow, writing a BrowserQL query, exporting it to code, and running it in n8n:
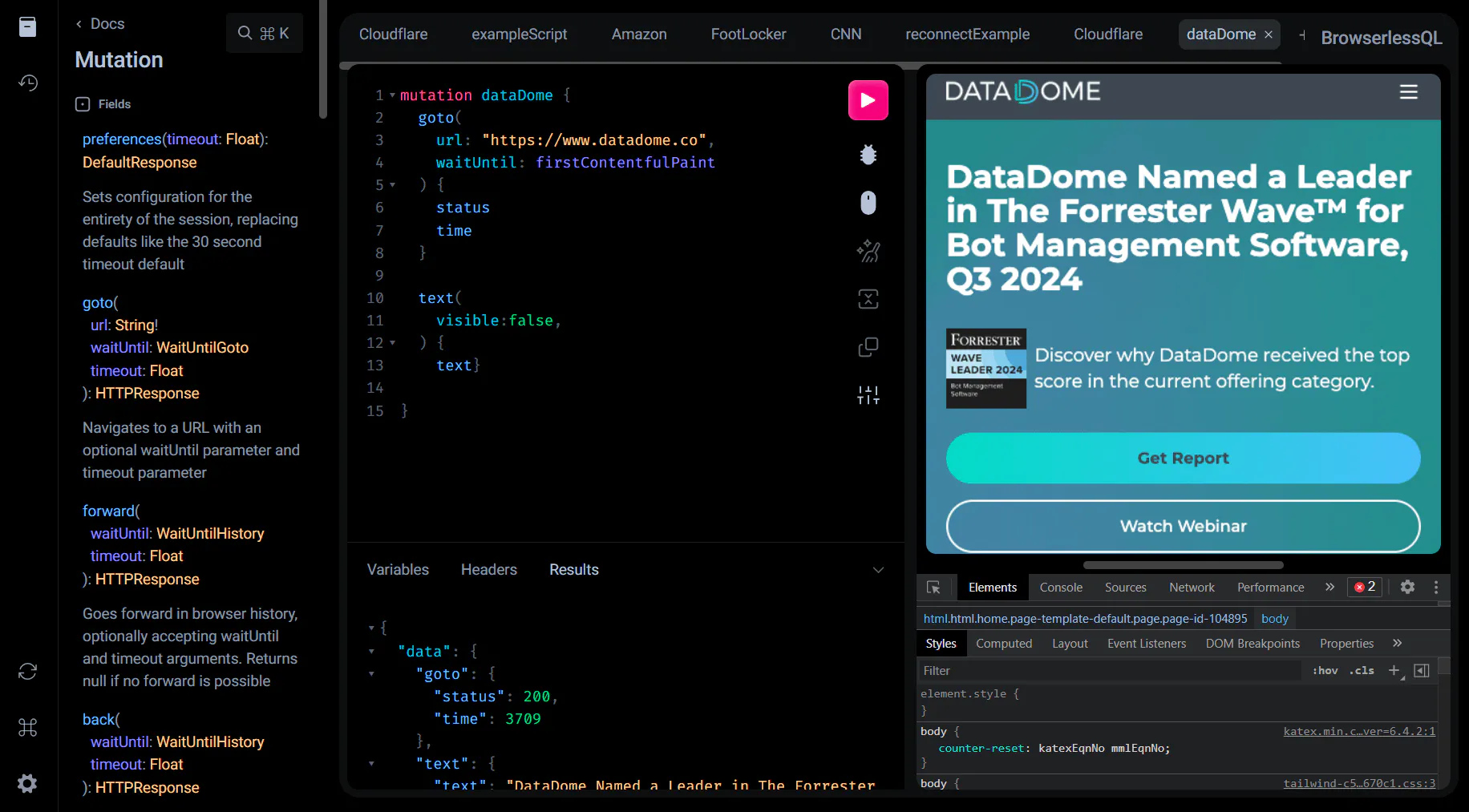
Specialized scraping IDE, with docs, debugging and browser view
The IDE is a result of our own struggles with debugging web automations. A live view of a local browser can’t always help you debug what’s going on in a production environment, while flicking between multiple doc sites is an easy way to lose focus.
Live browser and debugging views
We hate trying to troubleshoot block box errors from a REST API. Getting a 200 response because the page has loaded, but not getting the HTML you wanted is always annoying.
That’s why we feel a live browser view is essential.
You can see what’s really happening in the browser as we run your script, complete with any typing, mouse movements or captcha solving.
The Chrome debugging tools are also available, although having them on can sometimes trigger bot detectors. You can inspect a page as usual to find relevant CSS selectors or look at other details.
Fun Fact: Puppeteer and Playwright always turn on the debugger in the background, it’s one of those automation giveaways.
Inbuilt documentation
The IDE has inbuilt documentation to help minimize distractions from flicking between views. You can cmd + click within the editor to get the details about any query you’re writing.
Variables, headers and results
Like any good IDE, you can define relevant variables and headers for use in your code.
You can then also see all the responses from running the automations, such as times, extracted text or confirmed selectors.
Connecting unlocked sessions and cookies to AI agents or Puppeteer/Playwright
Once BrowserQL has got past a bot detector, you can then run further automations with an agent or other library.
Connect via a WebSocket
You can generate a WebSocket endpoint for connecting other tools to an approved browser session with reconnect(timeout: 1000):{browserWSEndpoint}
If you have existing Puppeteer or Playwright scripts, you can change the endpoint to have them run on our browsers.
The same goes for AI agents that need to interact with third party websites. Once the site has been approved, you can pass the endpoint over to your agent to run further queries.
Use the approval cookie
Once a browser has been approved by a bot detector, it’s typically given a cookie so that it gets instant approval for further page loads.
You can request the cookie to pass along to your other automations with cookies{cookies{path}}.
Reconnect other BrowserQL sessions
You can run multiple BrowserQL scripts with one browser instance by using our reconnect. To do this, request a browserQLEndpoint in the first script to use in further automations using reconnect(timeout: 1000):{browserWSEndpoint}.
This is useful if you don't want to repeat steps such as logging in and instead want to continue a browser session.
Also in the roadmap: clickVerify, spiders, pre-hydrated browsers and recording actions
Of course, we’ve got plenty more things we want to add to BrowserQL. These include:
Checking verification boxes within iframes and shadow DOMs
Ticking a verify box is usually easier said than done, now that they’re usually hidden within nested layers of iframes within shadow DOMs with iframes,
We'll soon be adding a clickVerify command to automatically look through these layers to find and tick a Captcha verification. This is especially useful on pages such as contact forms or login screens, where a verification is guaranteed to appear.
Note: If further verification such as 2FA is required, then you can use our Hybrid Automations to add a human-in-the-loop.
Inbuilt spidering
If you’re scraping changing sites, then you’re probably using spiders. It’s high up our road map so let us know if you’d like to beta test that functionality when it’s nearly ready.
Pre-hydration for speedy loading
Having to keep reloading the full CSS for a site isn’t very efficient. It’s why we’re looking at tactics such as pre-hydrating browsers or clever caching so that automations on popular sites can run more quickly.
Recording browser actions
As much as we love coding, just clicking around a page would be much easier. We’re working on ways to let you click, type and perform other actions, for us to then turn into code in our query language.
Exporting to other formats
cURL is great, but we also plan to support exporting directly to other languages.
Custom scripting service
Finally, if you would rather completely offload the work of setting up your automations, then we now offer a custom scriptng service. All you’ll need to do is tell us what data you want and we'll set up all the details, such as bot detection and managing concurrencies. you just get to make use of the JSON or other output.