Introduction
Web scraping can be tricky, especially with complex page layouts and unstructured text. This guide is here to help by showing you how to use BrowserQL and ChatGPT together. These tools make it much easier to extract raw text from websites and turn it into organized data, like JSON. The goal is simple: make web scraping faster and less hassle-free. BrowserQL pulls raw text from webpages, while ChatGPT uses natural language processing to structure that text meaningfully. By the end of this guide, you’ll see how combining these tools can save time, reduce effort, and bring more automation into your data workflows.
The Problem With Manually Programmed Scraping

Current Challenges in Web Scraping
Parsing web pages can feel like peeling layers of a messy, inconsistent onion. HTML structures often vary dramatically across sites and sometimes even within the same website.
They frequently update layouts or use dynamic content generation, which makes targeting specific elements a moving target. These inconsistencies force you to repeatedly tweak scrapers to keep up with changes, making the process unreliable and time-consuming.
Once the text is extracted, another hurdle arises: transforming unstructured, raw content into usable data formats like JSON. Raw text is rarely clean or ready for analysis. It often includes irrelevant information, inconsistencies, and missing fields.
Manually parsing and structuring this data is tedious and prone to errors, especially when processing large datasets. This manual work quickly becomes a bottleneck, undermining the efficiency of the entire workflow.
Dynamic content can also add complexity; for instance, discounted items on an E-commerce site may have a different CSS selector for the actual price, which could be missed when relying on a single set of locators. These variations underscore the need for flexibility by parsing each page individually or refining ChatGPT prompts for batch workflows.
Proposed Solution
BrowserQL simplifies web scraping by allowing you to extract text directly from web pages without grappling with messy HTML. It streamlines the process, giving you only the visible content you care about.
This approach saves time, eliminates irrelevant elements, and allows you to scale your scraping efforts without worrying about the underlying structure of the webpage.
Once the raw text is extracted, ChatGPT parses it into structured formats like JSON. Its natural language processing capabilities allow it to understand and organize unstructured text into clean, consistent datasets.
For simpler or static sites, ChatGPT can generate CSS locators from example pages. These locators can then be applied across similar pages, avoiding the need for individual parsing. This workflow speeds up data collection for batch scraping tasks while keeping things flexible for dynamic sites.
This combination of BrowserQL for precise extraction and ChatGPT for intelligent parsing creates a seamless, automated pipeline that handles the heavy lifting of web scraping, enabling you to focus on the insights rather than the mechanics.
Tools and Setup
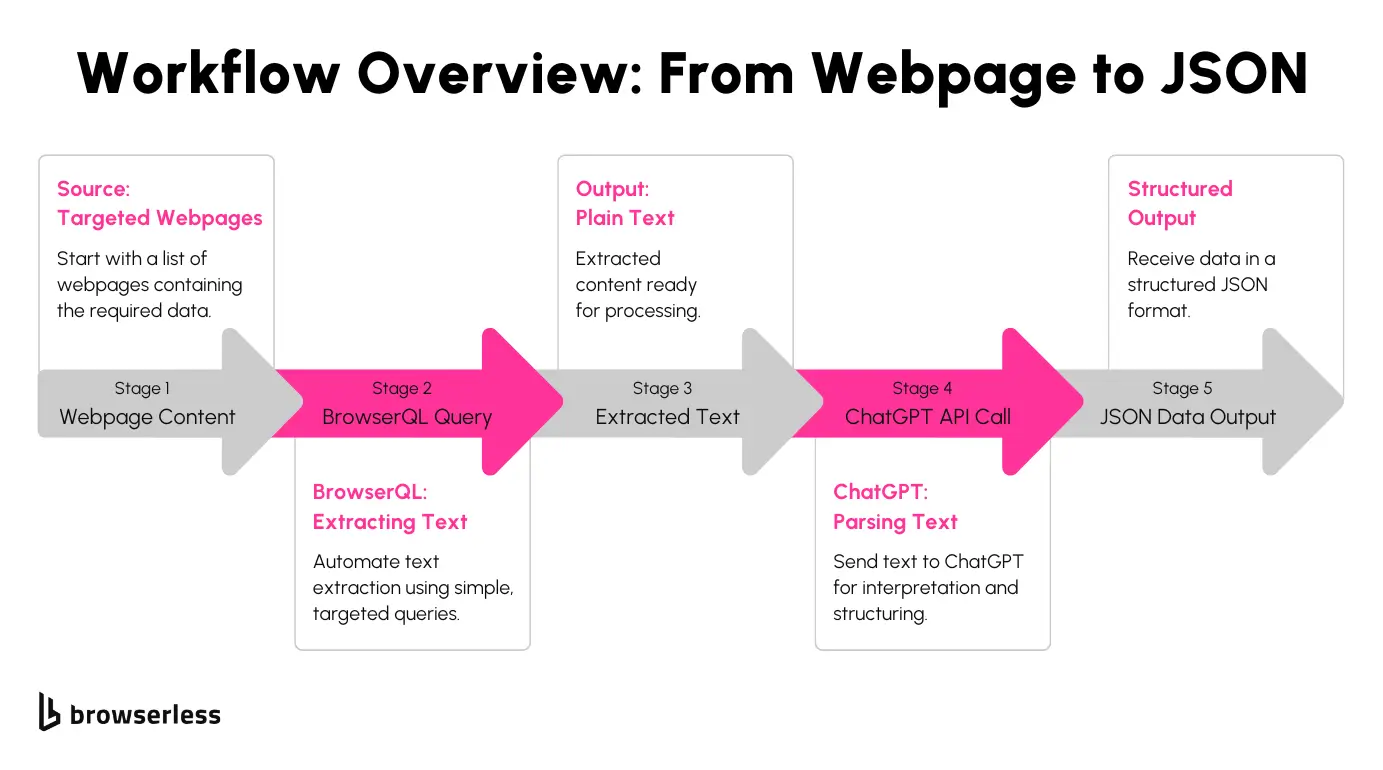
Now that we’ve outlined the proposed solution let’s dive into the tools that make it possible. These tools work together to simplify the extraction and structuring of web data, enabling you to focus on generating meaningful insights rather than managing the intricacies of scraping workflows.
BrowserQL
BrowserQL is designed for automating browser tasks and extracting web content as plain text. It allows you to interact with webpages programmatically, running queries to fetch the exact data you need.
What sets BrowserQL apart is its minimalistic and stealth-first design, which reduces the risk of detection by anti-scraping mechanisms. This makes it an excellent choice for tasks that demand high precision and reliability without constant interruptions caused by CAPTCHA challenges or IP blocks.
ChatGPT API
The ChatGPT API takes the extracted raw text and processes it into structured data formats, such as JSON. Using advanced natural language processing, ChatGPT understands the context of the text and organizes it into consistent, machine-readable outputs.
Whether you’re parsing product listings, customer reviews, or pricing data, the ChatGPT API provides a reliable way to bridge the gap between unstructured and structured data, making it an essential component for building automation pipelines.
Prerequisites
Before you get started, you’ll need to set up a couple of things. First, a free BrowserQL account and its editor are required to craft and run your queries.
You’ll also need an OpenAI API key for accessing the ChatGPT API. Both tools require some basic environment configuration, such as installing dependencies and setting up authentication, to ensure smooth integration into your workflow.
Workflow Overview
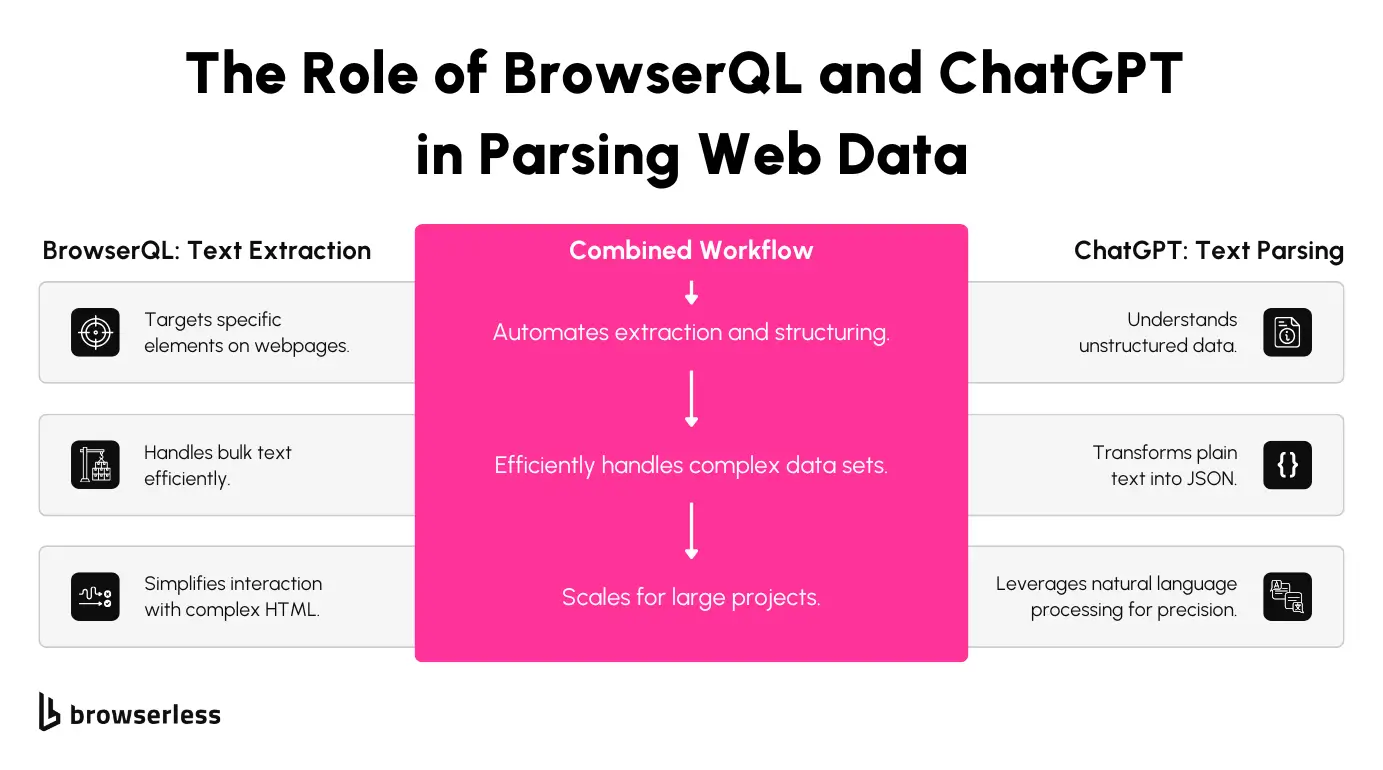
Let’s break down how BrowserQL and ChatGPT work together to seamlessly automate web data extraction and parsing. This step-by-step process takes you from raw web pages to structured JSON outputs, making it straightforward to integrate into your own projects.
Alternatively, instead of parsing every page individually, you can use ChatGPT to extract reusable CSS locators for scraping multiple pages with the same layout. This approach works well for static sites with consistent structures, saving time and API requests. However, for dynamic or context-sensitive content, individual page parsing is more reliable.
Step 1: Extracting Text with BrowserQL
The first step involves extracting raw text or HTML from web pages. BrowserQL is incredibly useful here, as it lets you craft queries that pinpoint specific elements on a page. This eliminates the need for manual HTML scraping and gives you clean data for further processing.
For example, you can grab information like product descriptions, prices, or customer reviews by targeting specific parts of a webpage.
Here’s a conceptual example of a BrowserQL query:
mutation ExtractPageText {
goto(url: "https://example.com/products/123", waitUntil: networkIdle) {
status
time
}
htmlContent: html(visible: true) {
html
}
}
This query opens the product page at the provided URL, waits for the page to fully load (network idle), and retrieves the visible HTML content. From here, you can use this raw HTML for further processing.
If you want to focus on specific elements, you can refine the query by using CSS selectors or XPath to extract only the text you need. This flexibility makes BrowserQL a great tool for targeting different types of web pages.
Step 2: Parsing Text with ChatGPT
Once you’ve extracted raw HTML or text, the next step is to turn this unstructured data into a structured format using ChatGPT. This step simplifies the messy process of parsing raw data into something useful, like a JSON file with fields such as product name, price, and rating.
Here’s an example of how you can use the ChatGPT API to parse raw text into JSON:
const inputText = "Product Name: Smartphone X\nPrice: $799\nRating: 4.5 stars";
const prompt = `Extract the following details from this text and return them as JSON: name, price, and rating.\n\nText: ${inputText}`;
const response = await fetch("https://api.openai.com/v1/completions", {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer YOUR_API_KEY`,
},
body: JSON.stringify({
model: "gpt-4",
prompt: prompt,
max_tokens: 100,
}),
});
const jsonData = await response.json();
console.log(jsonData.choices[0].text);
In this example, the API takes raw text (like product details) and processes it into a neat JSON object. This makes the data easy to analyze, store, or use in other applications.
It’s worth noting that ChatGPT models, such as gpt-3.5-turbo and gpt-4, have limitations in the size of input they can handle. The API might reject the request if the HTML content is too large. To work around this, you can use Cheerio to clean up the raw HTML and send only the relevant parts to ChatGPT. This keeps your requests efficient and avoids running into token size limits.
If you’re working with a batch of pages that share the same layout, you can ask ChatGPT to identify CSS selectors instead of parsing each page individually. For example, you could provide ChatGPT with a sample page and ask it to find reusable locators for elements like product names, prices, or descriptions. This one-time task can simplify scraping static sites.
Step 3: Automating the Workflow
To bring everything together, you can automate the entire workflow with a script. Depending on your use case, you can either:
- Automate individual page parsing: Ideal for dynamic sites where content or layout changes frequently. Each page is processed individually by sending it to ChatGPT, ensuring that dynamic elements like discounts or varying structures are captured accurately.
- Use extracted CSS locators to scrape multiple pages: Perfect for static sites with consistent layouts. In this workflow, you extract reusable CSS locators using ChatGPT from a single sample page and use those locators to scrape hundreds of similar pages without sending individual requests.
The script below fetches text from multiple URLs, processes the raw HTML with ChatGPT, and saves the results as structured data. Automation not only saves time but also scales easily to handle large datasets.
Here’s an example of how the automation might look in practice:
const urls = [
"https://example.com/products/123",
"https://example.com/products/456",
];
for (const url of urls) {
// Fetch raw HTML from BrowserQL
const extractedHtml = await fetchBrowserQL(url);
// Clean up the HTML with Cheerio (if necessary)
const cleanedHtml = extractRelevantHtml(extractedHtml);
// Parse the cleaned data with ChatGPT
const structuredData = await sendToChatGPT(cleanedHtml);
// Save the structured data to a CSV or JSON file
saveToCSV(structuredData);
}
With this setup, you can extract, parse, and save data from multiple web pages without manual intervention. It’s efficient, repeatable, and easily customizable for your specific use case.
Implementation
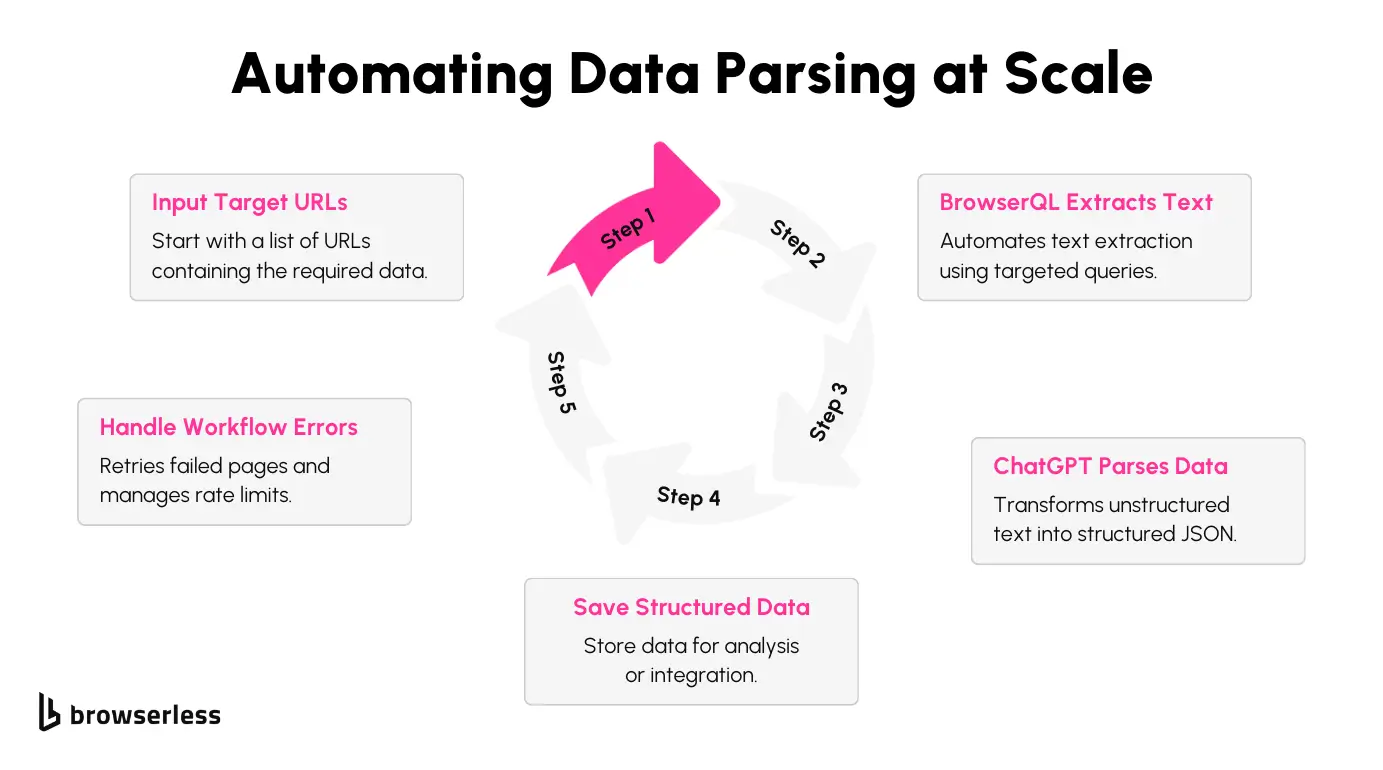
Now that we’ve explored the tools and the conceptual workflow, let’s put everything into practice with a real-world example. We’ll extract product details from eBay using BrowserQL and ChatGPT. The goal is to pull key information, like product titles and prices, and organize it in a clean, structured format.
This walkthrough will explain how each part of the script works. Let’s get hands-on and see it in action!
Step 1: Fetching Product HTML with BrowserQL
To start, we use BrowserQL to fetch the HTML content of the product page. BrowserQL makes loading the page easy, waiting for all network activity to complete and returning the visible content.
This ensures we only process what the user would see on the page. Here’s the function:
import fetch from "node-fetch"; // Import fetch for API requests
// BrowserQL API configuration
const BROWSERQL_URL = "YOUR_BROWSER_QL_URL"; // Replace with your URL
const BROWSERQL_API_KEY = "YOUR_BROWSERQL_API_KEY"; // Replace with your actual API key
/**
* Fetches the visible HTML content of a product page using BrowserQL.
* @param {string} url - The eBay product page URL.
* @returns {string|null} - The visible HTML content, or null if there's an error.
*/
async function fetchBrowserQLHtml(url) {
// GraphQL query to load the URL and extract visible HTML
const query = {
query: `
mutation {
goto(url: "${url}", waitUntil: networkIdle) {
status // HTTP status of the loaded page
time // Time taken to load the page
}
waitForTimeout(time: 3000) { time } // Wait for 3 seconds to allow additional content to load
htmlContent: html(visible: true) { html } // Extract visible HTML
}
`,
};
try {
console.log(`Fetching HTML content for: ${url}`); // Log the URL being processed
const response = await fetch(`${BROWSERQL_URL}?token=${BROWSERQL_API_KEY}`, {
method: "POST",
headers: { "Content-Type": "application/json" }, // Specify JSON content type
body: JSON.stringify(query), // Send the query to BrowserQL
});
// Parse the API response and return the HTML content
const data = await response.json();
return data?.data?.htmlContent?.html || null; // Return the HTML or null if not found
} catch (error) {
console.error(`Error fetching HTML for ${url}:`, error.message); // Log any errors
return null; // Return null on failure
}
}
This function handles errors gracefully and ensures the HTML is returned only when the page is fully loaded.
Step 2: Cleaning Up HTML with Cheerio
Now that we’ve grabbed the raw HTML from the webpage, it’s time to clean it up using Cheerio. eBay pages are packed with extra content, ads, scripts, and a ton of unrelated metadata. With Cheerio, we can focus on the specific details we actually need, like the product title and price, while ignoring the rest.
Why is this cleanup step so important? It comes down to the limitations of the ChatGPT API. If your target site has a consistent layout, you can use ChatGPT to extract reusable CSS locators during a one-time setup, as explained in the Workflow Overview. This approach bypasses the need to clean HTML for each page and allows you to scrape multiple pages efficiently. For example, instead of parsing raw HTML here, you can directly use CSS selectors to extract the required data in one go. Models like gpt-3.5-turbo and gpt-4 have input size restrictions.
For example, gpt-3.5-turbo can only handle 4,096 tokens per request, including both the input (our HTML) and the output (the structured data it returns). If we try to send the entire raw HTML file which can be huge it might exceed these limits, causing errors or incomplete results.
Using Cheerio to trim the HTML down to just the essentials means we’re working smarter, not harder. By sending a smaller, cleaner file to the ChatGPT API, we stay well within its limits while still getting the details we’re after. This approach ensures the API can focus on processing the meaningful data, rather than wasting tokens on irrelevant information.
import * as cheerio from "cheerio"; // Import Cheerio for parsing HTML
/**
* Cleans up the raw HTML content to extract product details like title and price.
* @param {string} html - Raw HTML content from the product page.
* @returns {string} - Cleaned-up content, ready for ChatGPT.
*/
function extractRelevantHtml(html) {
const $ = cheerio.load(html); // Load the HTML into Cheerio for parsing
// Extract the product title from the <title > tag
const title = $("title").text().trim();
// Extract the product price using multiple potential selectors
const price =
$(".x-price-primary span").first().text().trim() || // Primary price class
$('[itemprop="price"]').attr("content") || // Fallback for schema.org price
"Not found";
// Extract the meta description for additional context
const metaDescription = $('meta[name="description"]').attr("content") || "N/A";
// Prepare cleaned-up content for ChatGPT
return `
Title: ${title}
Meta Description: ${metaDescription}
Price: ${price}
`;
}
The extractRelevantHtml function uses multiple selectors for price to account for differences in page structure.
Step 3: Processing Data with ChatGPT
Next, we send the cleaned HTML to ChatGPT to extract structured data in JSON format. This step eliminates the need for complex manual parsing and lets ChatGPT handle the formatting. For simpler workflows, where site layouts are predictable, you can skip parsing each page individually and instead use CSS locators generated by ChatGPT. This alternative method reduces API calls and is especially useful for batch processing of pages.
/**
* Sends cleaned HTML content to ChatGPT and extracts structured product details.
* @param {string} cleanedHtml - Cleaned HTML content.
* @returns {Object} - Parsed JSON object with product details.
*/
async function parseWithChatGPT(cleanedHtml) {
const OPENAI_API_KEY = "YOUR_OPENAI_API_KEY"; // Replace with your OpenAI API key
// ChatGPT prompt to extract structured data from the product content
const prompt = `
Extract the following details from the provided product data:
- Product Title
- Price
Return the output as a valid JSON object.
Product Data:
${cleanedHtml}
`;
try {
console.log("Sending data to ChatGPT..."); // Log the interaction with ChatGPT
const response = await fetch("https://api.openai.com/v1/chat/completions", {
method: "POST",
headers: {
"Content-Type": "application/json", // Specify JSON content type
Authorization: `Bearer ${OPENAI_API_KEY}`, // Include the OpenAI API key
},
body: JSON.stringify({
model: "gpt-3.5-turbo", // Specify the model
messages: [{ role: "user", content: prompt }], // Include the prompt
max_tokens: 300, // Limit the output tokens
}),
});
const jsonResponse = await response.json();
// Ensure the response contains valid content
if (!jsonResponse.choices || !jsonResponse.choices[0]?.message?.content) {
throw new Error(
`Invalid response from ChatGPT: ${JSON.stringify(jsonResponse)}`,
);
}
// Parse the returned JSON content
return JSON.parse(jsonResponse.choices[0].message.content);
} catch (error) {
console.error("Error with ChatGPT API:", error.message); // Log API errors
return null; // Return null on failure
}
}
This function communicates with ChatGPT using a clear prompt and processes the response.
Step 4: Saving Results to a CSV File
Finally, we save the extracted data to a CSV file for easy access and analysis. Each product’s details are stored as a row.
import fs from "fs"; // Import file system for saving files
import { createObjectCsvWriter } from "csv-writer"; // Import CSV writer
// Configure the CSV writer
const csvWriter = createObjectCsvWriter({
path: "product-data.csv", // Output CSV file path
header: [
{ id: "title", title: "Product Title" },
{ id: "price", title: "Price" },
{ id: "url", title: "Product URL" },
],
});
/**
* Saves product data to a CSV file.
* @param {Array} results - List of product details to save.
*/
async function saveToCsv(results) {
if (results.length > 0) {
await csvWriter.writeRecords(results); // Write the records to CSV
console.log("Data saved to product-data.csv"); // Confirm data is saved
} else {
console.log("No data to save."); // Log if no data is available
}
}
Step 5: Running the Script
The script combines all the steps, processing multiple URLs and saving the extracted data. If you’re leveraging pre-extracted CSS locators, the workflow changes slightly. Instead of processing each page with ChatGPT, you can directly scrape data from multiple pages using the reusable locators identified during the setup phase.
const productUrls = [
"https://www.ebay.com/itm/256288496820",
"https://www.ebay.com/itm/116374540594",
];
/**
* Main function to process all product URLs and extract data.
*/
async function processProducts() {
const results = []; // Initialize an array to store results
for (const url of productUrls) {
try {
console.log(`Processing URL: ${url}`); // Log the URL being processed
const htmlContent = await fetchBrowserQLHtml(url); // Fetch HTML
if (!htmlContent) throw new Error("Failed to fetch HTML content.");
const trimmedHtml = extractRelevantHtml(htmlContent); // Clean HTML
console.log(`Trimmed HTML content:\n${trimmedHtml}`);
const structuredData = await parseWithChatGPT(trimmedHtml); // Send to ChatGPT
structuredData.url = url; // Add URL to the result
results.push(structuredData); // Save the result
console.log("Data Extracted:", structuredData);
} catch (error) {
console.error(`Failed to process ${url}:`, error.message); // Log errors
}
}
await saveToCsv(results); // Save results to CSV
}
processProducts(); // Run the script
After running the script, you’ll have a tidy CSV file with all the product details you sought. BrowserQL takes care of any anti-bot challenges, and ChatGPT makes data extraction effortless by giving you a nicely formatted JSON without the headache of figuring out tricky selectors. Feel free to tweak the script or add features to match your specific needs, it's flexible and ready for whatever you have in mind!
Conclusion
Using BrowserQL and ChatGPT together makes web scraping and data structuring much simpler. BrowserQL focuses on easily extracting data from websites, and ChatGPT transforms that raw data into structured formats that are ready to be used.
Once you have the basics, you can expand your workflows to handle even more complex parsing tasks. You could try crafting advanced ChatGPT prompts or experimenting with other AI tools to fine-tune your results.
Ready to see how this can work for you? Sign up for BrowserQL today and start automating your web scraping workflows.