Introduction
Scraping the web can be inefficient with traditional tools like Puppeteer or Scrapy, which struggle with session management and waste proxy bandwidth. They load a fresh browser for every page, so you can’t get the efficiencies that come from a consistent cache and cookies.
Reconnects simplify workflows by reusing browser sessions and caching data, cutting proxy usage by up to 90%, and reducing bot checks. This article explores reconnects, how to implement them, and how BrowserQL makes scaling easier while improving efficiency and cutting costs.
Do-It-Yourself (DIY) Approach

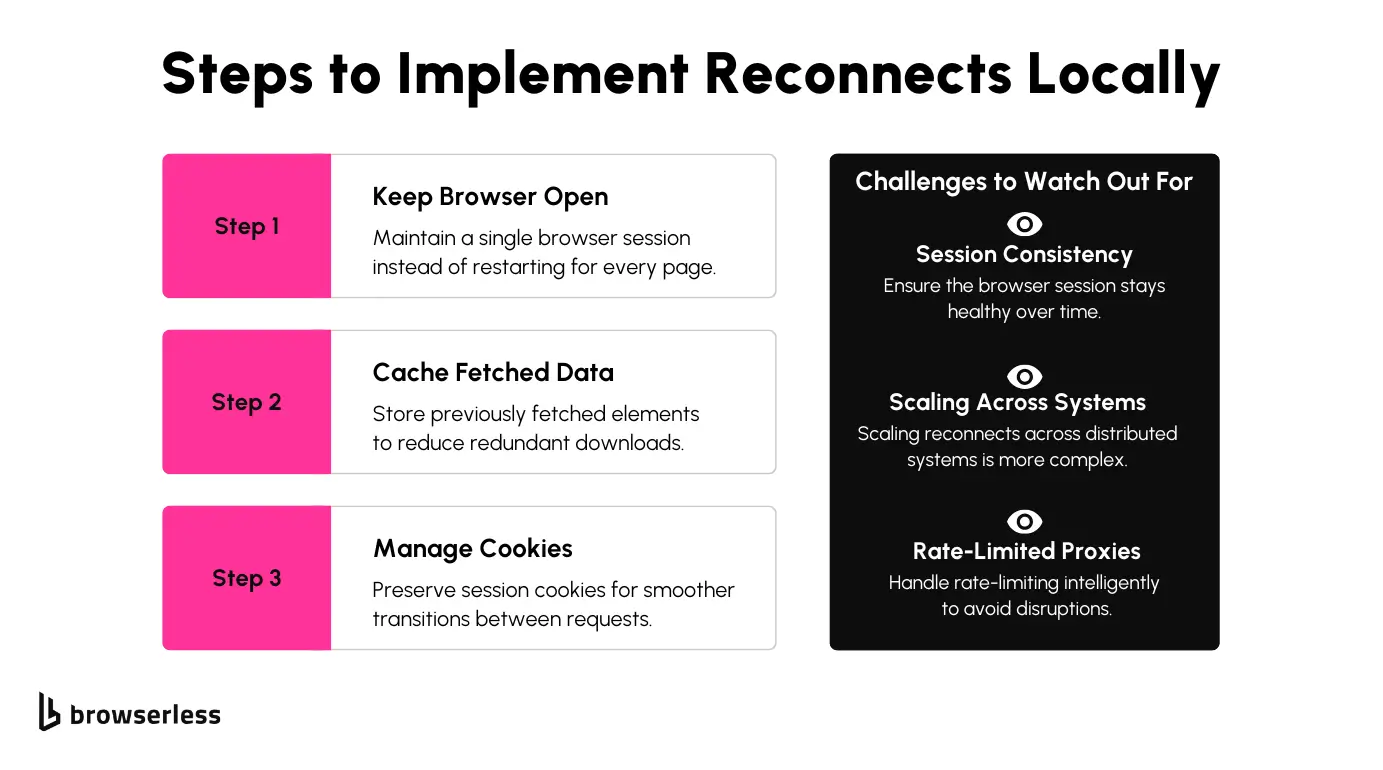
How to Implement Reconnects Locally
If you’re using Puppeteer or Playwright, one way to save time and reduce proxy usage is by keeping your browser session open and reconnecting to it instead of starting fresh for every page load.
This way, session states like cookies are retained, so you won’t have to repeatedly deal with login prompts or bot detection. It’s a simple adjustment that can make a big difference in efficiency.
Another trick is to cache any data you’ve already fetched. For example, if you’ve downloaded static elements or layouts that won’t change between requests, there’s no need to grab them again.
You’ll save bandwidth and significantly speed things up, especially when scraping pages that share similar structures. This is a smarter way to avoid wasting resources on redundant requests.
That said, this approach has its challenges. Keeping the browser session running smoothly over time can be tricky, so you’ll need to watch for memory issues or crashes that can disrupt the workflow.
With Puppeteer or Playwright, manually filtering unnecessary requests like images or ads can become tedious. It’s doable but not always the most efficient setup, especially for more complex websites.
Here’s what it would look like in practice using Puppeteer.
import puppeteer from "puppeteer";
// Function to launch a persistent Puppeteer session
async function scrapeWithReconnect() {
// Launch browser session with persistent settings
const browser = await puppeteer.launch({
headless: false, // Set to false to see browser in action
userDataDir: "./data/session", // Save session data here
});
const page = await browser.newPage();
await page.goto("https://google.com", { waitUntil: "networkidle2" });
// Extract page title
const title = await page.evaluate(() => document.title);
console.log("Page Title:", title);
// Reuse session for another request
await page.goto("https://www.google.com/search?q=iphone", {
waitUntil: "networkidle2",
});
const nextTitle = await page.evaluate(() => document.title);
console.log("Next Page Title:", nextTitle);
// Keep session running
console.log("Keeping session open. Close manually when done.");
}
// Run the scraper
scrapeWithReconnect();
While the example above works, you’ll likely run into CAPTCHA challenges. In this case, we first visit Google.com and then, within the same session, send a search query for an iPhone. However, when making that request, we trigger a CAPTCHA.
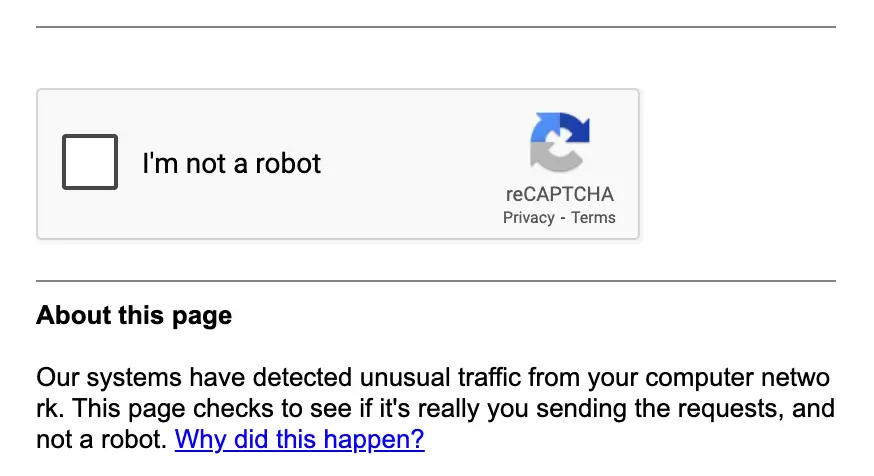
While Google is expected to have strong anti-bot detection, many modern websites are implementing similar protections, and these systems are continuously improving. As you can see, traditional scraping techniques, such as sending automated requests without handling bot challenges, often won’t work reliably.
Limitations
While reconnecting and caching work well for small-scale or local use, scaling them across multiple machines has some added hurdles. Managing multiple sessions consistently and dealing with cookie persistence, session timeouts, and proxy rate limits can get overwhelming. These things are manageable on a smaller scale but can feel clunky as you scale up your scraping workflows.
Potential Enhancements for Scraping Workflows
Reject Query Features to Consider
Avoid unnecessary reloading of unchanged elements.
One way to improve performance and reduce proxy usage is by targeting only the needed elements. Instead of loading everything on a page, you can focus on specific data, such as images, media files, and other non-critical assets. This reduces your bandwidth and makes your workflows faster and leaner.
BrowserQL’s reject API
The reject API in BrowserQL simplifies this process. It lets you configure your scraper to skip over unnecessary requests, like images, videos, or other large files that don’t contribute to your data goals. For example, you can block all requests for .jpg, .png, or .mp4 file types with just a few settings. This approach saves resources and reduces the chances of being flagged by anti-scraping mechanisms.
Reject Query with BrowserQL
Using BrowserQL’s reject API is straightforward. You specify the request types you want to block in your query setup, and it takes care of the rest. For instance, you might configure it to bypass requests for stylesheets or media while loading essential scripts and data points. This optimization can significantly affect performance and cost-effectiveness for larger-scale scraping tasks.
Maintain browser state without starting from scratch
Maintaining an active browser session can save significant time when scraping multiple pages. Instead of initializing a new session for every request, you can keep the browser open, preserving cookies, session data, and other states. This helps reduce unnecessary reloading and improves the speed of your scraping workflows.
Using Proxies To avoid IP bans while balancing proxy usage
You can implement proxy chains rotating between IPs if you work with proxies. This approach prevents individual proxies from being overused and lowers the risk of being blocked. Applying proxies to specific requests, like those that interact with sensitive endpoints, can help you balance efficiency and caution.
Scalability Challenges
While reconnects and selective proxying are effective for local setups, scaling these workflows to distributed systems introduces additional challenges. Handling session states, cookie management, and proxy rate limits becomes more complex when dealing with multiple nodes. These workflows need careful planning to stay consistent and reliable as the scale increases.
Leveraging Reconnects with BrowserQL
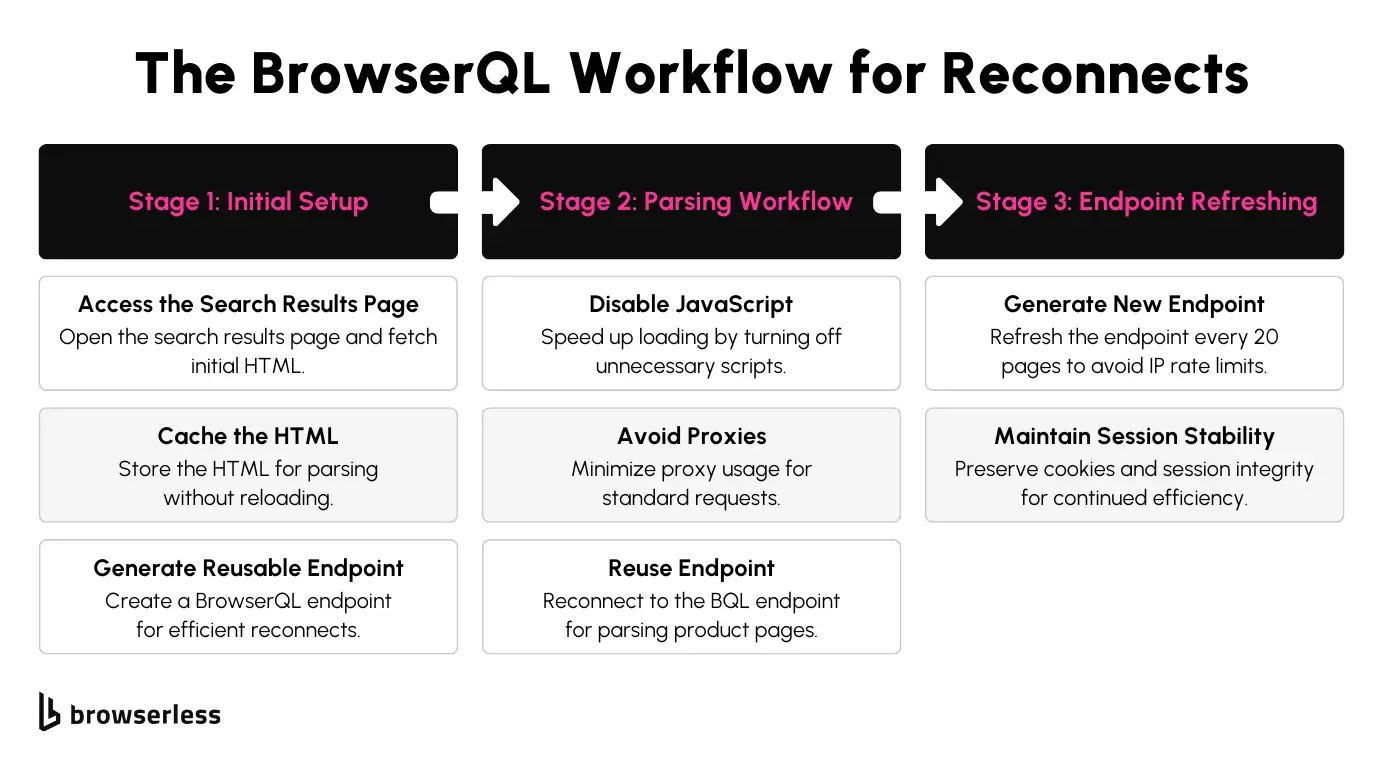
Initial Setup
With BrowserQL, you can quickly reduce unnecessary reloading and resource usage by setting up reconnects. Start by accessing a search results page and fetching the HTML content that needs parsing. From there, create a reusable BQL endpoint to reconnect to the same session. This eliminates the need to restart every page, which is especially useful when working with large datasets.
Let's look at an example by setting up a persistent browser session with BrowserQL (BQL) and generating a Reconnect URL. This allows future requests to use the same session instead of opening a new one, reducing proxy usage and speeding up scraping.
import fetch from "node-fetch";
// Set your BrowserQL API key
const API_KEY = "YOUR_BQL_API_KEY";
const BQL_ENDPOINT = "https://production-sfo.browserless.io/chromium/bql";
// Define the first query to open a session and get the reconnect URL
const firstQuery = `
mutation StartSession {
goto(url: "https://example.com/search?q=laptops", waitUntil: networkIdle) {
status
}
reconnect(timeout: 60000) { # Keep session open for 60 seconds
BrowserQLEndpoint
}
}
`;
async function startBQLSession() {
try {
const response = await fetch(BQL_ENDPOINT, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${API_KEY}`,
},
body: JSON.stringify({ query: firstQuery }),
});
const data = await response.json();
console.log("Reconnect Endpoint:", data.data.reconnect.BrowserQLEndpoint);
return data.data.reconnect.BrowserQLEndpoint;
} catch (error) {
console.error("Error starting BQL session:", error);
}
}
// Run the session setup
startBQLSession();
What’s happening here?
Our script launches a new browser session using BrowserQL.It navigates to a search results page and keeps the session open for 60 seconds. The Reconnect URL is printed, allowing future queries to reuse this session instead of starting fresh.
Parsing Workflow
When extracting specific data points, BrowserQL allows you to combine reconnects with its reject API for more efficient workflows. You can block requests for unnecessary elements, such as images or CSS files, minimizing bandwidth usage and proxy load.
Disabling JavaScript can boost the speed of individual product pages, especially when dynamic rendering isn’t required. Reusing a stable BQL endpoint ensures faster page access while keeping the session state intact.
We have a Reconnect URL, so we can use it to fetch product titles from the search results page without reloading everything. This saves bandwidth and speeds up scraping.
import fetch from "node-fetch";
// Replace this with the reconnect URL obtained from the first script
const RECONNECT_BQL_ENDPOINT = "YOUR_RECONNECT_BQL_ENDPOINT_HERE";
// Define the query to extract product titles
const secondQuery = `
mutation ScrapeProductTitles {
text(selector: ".product-title") {
text
}
}
`;
async function fetchWithReconnect() {
try {
const response = await fetch(RECONNECT_BQL_ENDPOINT, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ query: secondQuery }),
});
const data = await response.json();
console.log("Extracted Product Titles:", data.data.text.text);
} catch (error) {
console.error("Error fetching data:", error);
}
}
// Run the reconnect query
fetchWithReconnect();
What’s happening here?
Once the script connects to the existing session, it queries the product titles from the search results page instead of opening a new browser. Since no new page loads occur, proxy usage is minimized, and scraping is faster.
Endpoint Refreshing
Refreshing your BQL endpoint every 20 pages is a practical way to avoid hitting IP rate limits. This keeps your scraping sessions stable, prevents detection, and allows consistent data extraction across multiple pages. Automating this refresh process can save time and smooth your workflow, even during large-scale operations.
Here’s how you could implement it:
import fetch from "node-fetch";
const API_KEY = "YOUR_BQL_API_KEY";
const BQL_ENDPOINT = "https://production-sfo.browserless.io/chromium/bql";
// Define the query to refresh the reconnect endpoint
const refreshQuery = `
mutation RefreshSession {
reconnect(timeout: 60000) { # Extend session timeout
BrowserQLEndpoint
}
}
`;
async function refreshSession() {
try {
const response = await fetch(BQL_ENDPOINT, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${API_KEY}`,
},
body: JSON.stringify({ query: refreshQuery }),
});
const data = await response.json();
console.log("New Reconnect Endpoint:", data.data.reconnect.BrowserQLEndpoint);
return data.data.reconnect.BrowserQLEndpoint;
} catch (error) {
console.error("Error refreshing session:", error);
}
}
// Run session refresh every 20 pages
const PAGE_LIMIT = 20;
let pagesScraped = 0;
let reconnectEndpoint = "YOUR_INITIAL_RECONNECT_ENDPOINT_HERE";
async function scrapePage() {
if (pagesScraped >= PAGE_LIMIT) {
console.log("Refreshing session...");
reconnectEndpoint = await refreshSession();
pagesScraped = 0; // Reset page count
}
const pageQuery = `
mutation ScrapeNextPage {
text(selector: ".product-title") {
text
}
}
`;
try {
const response = await fetch(reconnectEndpoint, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ query: pageQuery }),
});
const data = await response.json();
console.log(`Scraped Page ${pagesScraped + 1} Data:`, data.data.text.text);
} catch (error) {
console.error("Error scraping page:", error);
}
pagesScraped++;
}
// Run scraping process for multiple pages
(async () => {
for (let i = 0; i < 100; i++) {
// Scrape 100 pages
await scrapePage();
}
})();
What’s happening here?
The script refreshes the Reconnect URL every 20 pages to avoid IP bans. This allows continuous scraping without getting flagged. The session remains stable, ensuring smooth and efficient data extraction.
Benefits of Scraping Hidden APIs
Re-reconnects are a solid tool for hiding APIs that require session persistence. They allow you to maintain approval cookies and other session-dependent data, often needed for secure API calls. This is especially helpful for handling authenticated requests or workflows that involve session tracking across multiple pages.
Comparing Scraping Approaches
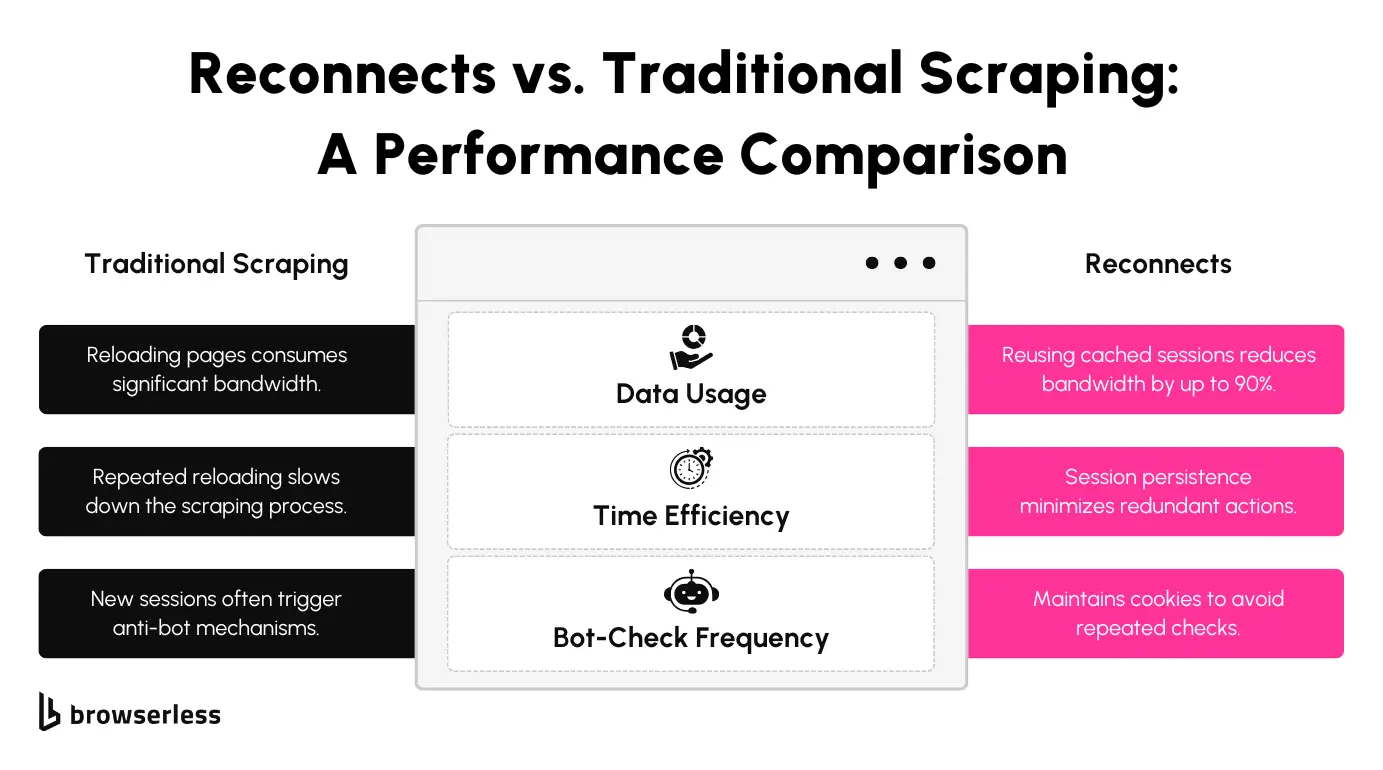
Reconnects vs. Traditional Methods
Using traditional scraping tools, every page load pulls non-essential elements like images, CSS, or ads. This inflates data usage and consumes proxies faster, especially for sites with heavy content. By contrast, BrowserQL’s reject API lets you filter out these unnecessary requests. Combining this with reconnects can significantly reduce proxy usage by up to 90% less data by skipping redundant content and reusing cached sessions.
For example, scraping 100 pages traditionally involves repeatedly reloading the full content for each page, leading to high data consumption. With reconnects, the browser session remains active, cached content is reused, and requests for elements like media files are skipped. The result is a streamlined workflow that dramatically reduces bandwidth usage and the burden on proxies.
To illustrate this further, let's run through a typical Puppeteer script to scrape multiple pages and look at what’s causing inefficiencies.
import puppeteer from "puppeteer";
async function scrapeTraditional() {
for (let i = 0; i < 5; i++) {
console.log(`Scraping page ${i + 1}...`);
// Start a new browser instance for each request
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Navigate to the page
await page.goto(`https://example.com/products?page=${i + 1}`, {
waitUntil: "networkidle2",
});
// Extract product titles
const titles = await page.evaluate(() =>
Array.from(document.querySelectorAll(".product-title")).map(
(el) => el.innerText,
),
);
console.log("Extracted Titles:", titles);
// Close the browser (starting fresh on next loop)
await browser.close();
}
}
scrapeTraditional();
Why is this inefficient?
- A new browser instance is launched for every request, which is slow and wasteful.
- All resources, including images, CSS, and JavaScript, are loaded again.
- Proxies are overused, increasing costs and risk of being blocked.
- Unnecessary CAPTCHA triggers due to lack of session persistence.
So now we see the issues with a more traditional approach; let's look at a more efficient method that maintains an active session and reuses it across multiple requests, eliminating redundant loading.
import fetch from "node-fetch";
const API_KEY = "YOUR_BQL_API_KEY";
const BQL_ENDPOINT = "https://production-sfo.browserless.io/chromium/bql";
// Define the first query to start the session and store the reconnect URL
const startSessionQuery = `
mutation StartSession {
goto(url: "https://example.com/products?page=1", waitUntil: networkIdle) {
status
}
reconnect(timeout: 120000) { # Keep session open for 2 minutes
BrowserQLEndpoint
}
}
`;
async function startBQLSession() {
try {
const response = await fetch(BQL_ENDPOINT, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${API_KEY}`,
},
body: JSON.stringify({ query: startSessionQuery }),
});
const data = await response.json();
console.log("Reconnect URL:", data.data.reconnect.BrowserQLEndpoint);
return data.data.reconnect.BrowserQLEndpoint;
} catch (error) {
console.error("Error starting BQL session:", error);
}
}
// Fetch data using reconnect
async function fetchWithReconnect(reconnectUrl, pageNum) {
const query = `
mutation ScrapePage {
goto(url: "https://example.com/products?page=${pageNum}", waitUntil: networkIdle) {
status
}
productTitles: text(selector: ".product-title") {
text
}
}
`;
try {
const response = await fetch(reconnectUrl, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ query }),
});
const data = await response.json();
console.log(`Page ${pageNum} Titles:`, data.data.productTitles.text);
} catch (error) {
console.error("Error fetching page:", error);
}
}
// Run the optimized BQL scraping workflow
(async () => {
const reconnectUrl = await startBQLSession();
for (let i = 1; i <= 5; i++) {
await fetchWithReconnect(reconnectUrl, i);
}
})();
Why is this better?
- Reuses the same browser session, saving time and bandwidth.
- Avoids unnecessary page reloads, reducing proxy and CAPTCHA triggers.
- Faster execution by keeping assets cached across requests.
- Less load on proxies, improving IP reputation, and lowering costs.
Conclusion
Scraping workflows don’t have to be clunky or expensive. Reconnects offer a practical, efficient way to reduce proxy usage, speed up workflows, and handle even complex scraping tasks more smoothly. Tools like BrowserQL make it even easier to implement reconnects at scale, letting you focus on getting the data you need without all the headaches. Whether you’re looking to optimize a few pages or handle large-scale scraping, reconnects are a game-changer. If you’re ready to take your scraping workflows to the next level, try reconnects and see how BrowserQL can simplify your process. Try BQL today.
FAQ
1. How does reconnecting browser sessions reduce proxy usage?
Reconnecting lets scrapers reuse an active session instead of starting fresh each time, saving bandwidth and avoiding repeated logins. BrowserQL's reconnect API keeps sessions open, minimizing proxy requests and reducing detection risks.
2. Why use BrowserQL instead of Puppeteer or Playwright for scraping?
BrowserQL automates JavaScript execution, CAPTCHA solving, and session management, eliminating the need for constant browser restarts. It’s faster, requires fewer resources, and simplifies large-scale scraping compared to Puppeteer or Playwright.
3. How does BrowserQL’s reject API improve scraping efficiency?
The reject API blocks unnecessary requests like images and ads, reducing bandwidth usage and speeding up scraping. This prevents loading non-essential content, making extractions more efficient while lowering proxy costs.
4. What’s the best way to scrape JavaScript-heavy websites?
Use BrowserQL to handle JavaScript execution on the server side, avoiding needing local headless browsers. Combining reconnects and the reject API speeds up requests, reduces proxy usage, and bypasses anti-bot measures efficiently.