Introduction
Cloudflare has become a go-to solution for protecting websites from bots, bad actors, and DDoS attacks. While this protection is great for website owners, it presents significant challenges for scrapers.
Cloudflare has many layers designed to block automated traffic, from bot detection algorithms to JavaScript challenges and TLS fingerprinting. For developers and data professionals, bypassing these defenses can feel like a complex puzzle.
This article explores proven techniques to bypass Cloudflare’s protection, including IP rotation, browser emulation, and handling JavaScript challenges.
Understanding Cloudflare's Bot Protection
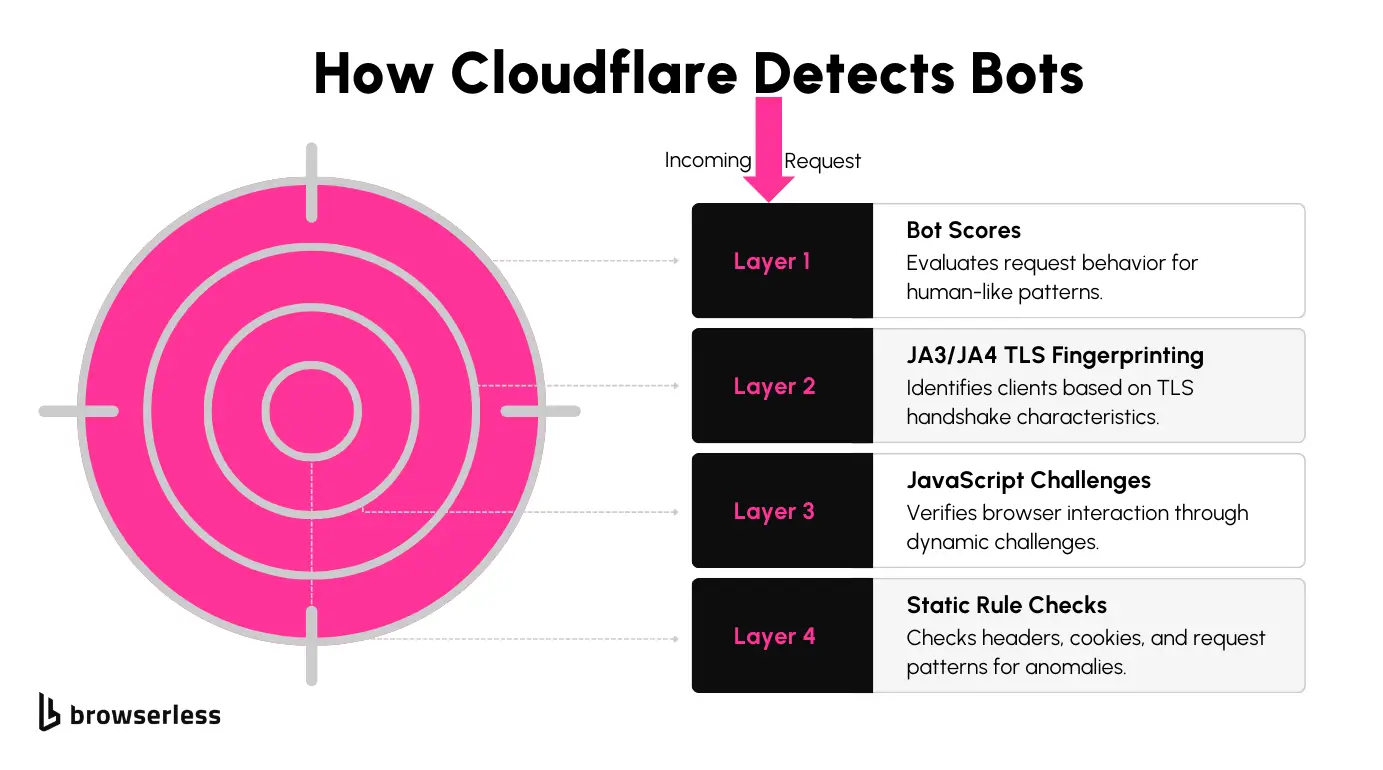
Cloudflare’s bot protection system is designed to differentiate between legitimate users and automated bots. It uses techniques to analyze requests, flag suspicious behavior, and block unauthorized access. Here are the key layers of protection:
- Bot Scores: Each request is assigned a score based on how "human-like" its behavior appears. Lower scores indicate higher suspicion.
- Detection IDs: Static rules identify patterns such as unusual headers, missing browser metadata, or abnormal request frequencies.
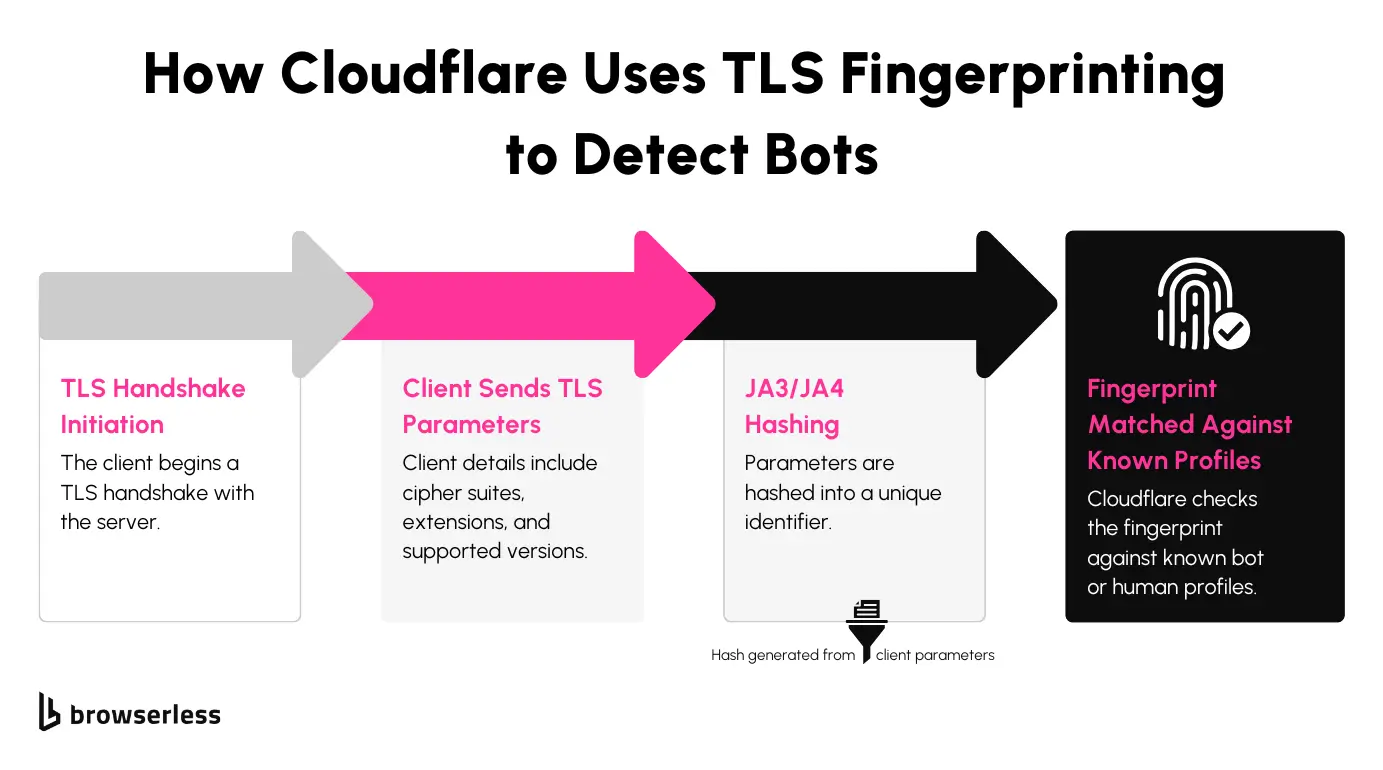
- JA3/JA4 Fingerprinting: Cloudflare evaluates the unique signature of the TLS handshake to identify the client and detect mismatches with known browser profiles.
- JavaScript Challenges: Scripts are dynamically injected into pages to verify browser interaction. To pass the challenge, JavaScript must be executed.
Impact on Scraping
Cloudflare’s protections significantly complicate automated scraping. Suspicious requests are blocked outright, often leaving pages inaccessible to non-human clients.
For scrapers, this means handling challenges like session persistence, managing evolving detection mechanisms, and overcoming dynamic JavaScript challenges. These hurdles make maintaining an effective scraping workflow more complex and time-consuming.
Bypassing Cloudflare's Protections

Rotating IP Addresses
Switching IP addresses frequently is a simple yet powerful way to avoid rate limits and bans when scraping Cloudflare-protected sites. Rotating your IPs spreads requests across multiple addresses, making them look more natural.
Using proxy pools or residential proxies is a great way to achieve this. Proxy pools rotate through a list of IPs automatically, while residential proxies mimic real user activity, making your requests less likely to get flagged.
Simulating Human-Like Behavior
Headless browsers like Puppeteer and Playwright can make your scraping look much more natural by mimicking how real users interact with a website.
These tools can execute JavaScript, handle cookies, and replicate actions like scrolling, clicking, and navigation. You can also tweak settings like headers, viewport sizes, and other browser features to make your scraper harder to detect. It’s a straightforward way to add a human-like touch to your automation.
Overcoming TLS Fingerprinting (JA3/JA4)
TLS fingerprinting is a tricky layer of detection that examines how a client connects to a website during the TLS handshake. To bypass this, you can adjust your scraper’s handshake parameters to match those of common browsers. You can tweak things like supported cipher suites and TLS versions so your requests look identical to legitimate browser traffic, reducing the chances of detection.
Handling JavaScript Challenges
Cloudflare often injects JavaScript challenges to confirm that a real browser is accessing the site. Tools like Puppeteer and Playwright shine here, as they can execute these challenges without breaking a sweat.
They handle the scripts automatically, keep session data intact, and let your scraper progress without interruption. So you can focus on obtaining the needed data without worrying about manual interventions for every challenge.
Here’s an example of how you could rotate IPs, simulate human behavior, modify TLS fingerprinting (JA3), and handle JavaScript challenges using Puppeteer and a proxy manager.
Be sure to replace the example proxies with your own and have the Puppeteer, HTTP proxy agent, and Puppeteer extra stealth plugin installed.
import puppeteer from "puppeteer-extra";
import StealthPlugin from "puppeteer-extra-plugin-stealth";
import HttpsProxyAgent from "https-proxy-agent";
// Use stealth plugin to bypass detection
puppeteer.use(StealthPlugin());
// List of proxy servers (replace with actual proxy credentials)
const proxies = [
"http://username:password@proxy1:port",
"http://username:password@proxy2:port",
"http://username:password@proxy3:port",
];
// Cloudflare-protected target URL
const targetUrl = "https://www.cloudflarechallenge.com";
async function scrapeWithBypass() {
for (let proxy of proxies) {
try {
console.log(`Trying proxy: ${proxy}`);
// Configure proxy settings
const browser = await puppeteer.launch({
headless: false,
args: [`--proxy-server=${proxy}`], // Apply rotating proxy
});
const page = await browser.newPage();
await page.setUserAgent(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
);
// Go to Cloudflare-protected site
await page.goto(targetUrl, { waitUntil: "domcontentloaded" });
// Wait to allow Cloudflare's JS challenge to execute
await page.waitForTimeout(5000);
// Extract text from page after challenge
const pageContent = await page.evaluate(() => document.body.innerText);
console.log("Page content extracted:", pageContent);
await browser.close();
break; // Stop looping once a proxy works
} catch (error) {
console.log("Proxy failed, trying next:", error);
}
}
}
scrapeWithBypass();
What This Does:
- Rotates IPs with a proxy list to avoid rate limits.
- Uses Puppeteer’s Stealth Plugin to prevent bot detection.
- Sets custom TLS/JA3-compatible headers for a human-like request.
- Waits for JavaScript challenges to execute, ensuring access.
- Extracts page content only after Cloudflare’s checks are bypassed.
The DIY approach can work, but it comes with limitations. Despite the different measures we tested, Cloudflare’s bot detection still blocked many attempts. This brings us to open-source tools designed to bypass Cloudflare let’s take a closer look at how they perform.
Exploring Open Source Tools for Bypassing Cloudflare
Several open-source libraries are available to help bypass Cloudflare's protections. Popular options include FlareSolverr and Cloudscraper. FlareSolverr integrates with headless browsers to handle Cloudflare challenges, while Cloudscraper simplifies bypassing static checks and CAPTCHA challenges. These tools provide solid starting points for bypassing basic protections, especially when working on smaller-scale projects or exploring scraping techniques.
Drawbacks of Using Free Options
We tested Cloudscraper and FlareSolverr to see how well they could handle Cloudflare’s protections. The results were hit-or-miss—many requests failed with errors like blocked access and unexpected responses. Even with stealth scraping settings, these tools struggled with JavaScript challenges and advanced bot detection, making scraping unpredictable.
One big downside of these free tools is their reliance on community updates. When Cloudflare tightens its security, it often breaks, and fixes aren’t always immediate.
If updates are slow or inconsistent, you could spend more time troubleshooting than scraping. While scraping can sometimes work, it requires hands-on maintenance, which isn’t ideal for long-term projects.
Another challenge is that open-source projects can be abandoned, meaning there are no updates or support when you need them. Since Cloudflare’s defenses are always evolving, tools that worked yesterday might fail tomorrow.
Scraping protected sites also involves legal and ethical considerations, from IP bans to policy violations. If you need something reliable, pairing stealth techniques with a well-maintained tool like BrowserQL can save you time and frustration.
How BQL Simplifies Bypassing Cloudflare

Automated JavaScript Execution
Cloudflare’s JavaScript challenges can be a real headache for scrapers, but BQL takes care of them automatically. Instead of spending time writing custom scripts to handle these challenges, you can let BQL do the heavy lifting. This built-in feature simplifies the process and lets you focus on getting the data you need without getting bogged down in technical workarounds.
IP and Session Management
Managing proxies and sessions can get messy quickly, especially when scaling up. BQL has you covered with built-in support for rotating proxies and maintaining sessions. It seamlessly handles these tasks in the background, helping you avoid rate limits and bans while keeping your scraping sessions intact. This makes it much easier to stay efficient, even for high-volume scraping.
Browser Emulation
To avoid detection, your scraper needs to act like a real browser, and BQL effortlessly does this. It lets you configure browser headers and TLS fingerprints to match popular browsers so your requests blend in with regular traffic. This added layer of realism helps bypass anti-bot measures and keeps your scraping workflow running smoothly.
Customizable Queries
BQL’s GraphQL-like queries make targeting the data you want super flexible. Instead of loading unnecessary page parts, you can focus on specific elements like product details or pricing. This saves time and bandwidth and minimizes the chances of your requests being flagged. It's a smarter way to scrape without wasting resources.
As we saw in the first example, manually managing proxy rotation and bot detection can be a hassle. To make things easier, let’s use BrowserQL (BQL) to handle Cloudflare challenges, solve CAPTCHAs, and keep sessions active automatically.
Here’s what it could look like:
import fetch from "node-fetch";
const API_KEY = "YOUR_BQL_API_KEY";
const BQL_ENDPOINT = "https://production-sfo.browserless.io/chromium/bql";
// GraphQL mutation to bypass Cloudflare and extract page data
const query = `
mutation ScrapeProtectedPage {
# Step 1: Visit the Cloudflare-protected page
goto(url: "https://www.cloudflarechallenge.com", waitUntil: networkIdle) {
status # Returns HTTP status (e.g., 200 for success)
}
# Step 2: Verify and solve Cloudflare's JS challenge if detected
verify(type: cloudflare) {
found # True if a Cloudflare challenge was detected
solved # True if successfully bypassed
time # Time taken to bypass challenge
}
# Step 3: Solve reCaptcha if present
solve(type: recaptcha) {
found # True if an reCaptcha was detected
solved # True if solved successfully
time # Time taken to solve CAPTCHA
}
# Step 4: Extract protected content from the page
extractedText: text(selector: ".protected-content") {
text # Retrieves text from the protected page
}
}
`;
async function scrapeWithBQL() {
try {
const response = await fetch(BQL_ENDPOINT, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${API_KEY}`, # Securely pass API key
},
body: JSON.stringify({ query }),
});
const data = await response.json();
console.log("Extracted Content:", data.data.extractedText.text);
} catch (error) {
console.error("BQL Scraping Failed:", error);
}
}
scrapeWithBQL();
What This Does:
- Bypasses Cloudflare’s anti-bot protections automatically.
- Solves Cloudflare’s JavaScript and CAPTCHA challenges.
- Extracts data from a Cloudflare-protected site without needing a headless browser.
- Uses BrowserQL’s built-in session management for efficiency and scalability.
Optimizing Your Workflow with BQL
Improving Scraping Speed
BQL’s endpoint-based design is built to handle multiple requests efficiently. Once you set up an endpoint, you can reuse it across multiple requests without reconfiguring settings repeatedly. This streamlined approach reduces overhead and speeds up data extraction, especially for workflows with high-frequency requests.
Reducing Complexity
Manually managing proxies, headers, and session configurations can quickly become overwhelming. BQL simplifies this process by handling these configurations out of the box. It handles complex setups like proxy rotation and browser header management, so you can focus on the data instead of constantly tweaking your scraper.
Scaling Efficiently
When scaling up to scrape hundreds or thousands of pages, manual adjustments just don’t cut it. BQL is designed to scale effortlessly. Its automation and endpoint management make it easy to handle large-scale scraping projects while maintaining consistent performance, no matter how much data you’re processing.
Avoiding IP Bans
To minimize detection, BQL includes adaptive IP rotation and request throttling. These features allow you to manage the pace of requests and switch proxies dynamically, reducing the chances of being flagged or banned. With these protections, your workflow stays reliable and uninterrupted, even for long scraping sessions.
Let’s implement this with this snippet that sends multiple requests to a Cloudflare-protected site, optimizing for large-scale scraping while minimizing detection and rate limits.
import fetch from "node-fetch";
const API_KEY = "YOUR_BQL_API_KEY";
const BQL_ENDPOINT = "https://production-sfo.browserless.io/chromium/bql";
// Function to fetch multiple pages efficiently
async function scrapeMultiplePages(pages) {
for (let i = 1; i <= pages; i++) {
const query = `
mutation ScrapeMultiplePages {
# Step 1: Visit each page
goto(url: "https://www.cloudflarechallenge.com/page=${i}", waitUntil: networkIdle) {
status # HTTP status (200 if successful)
}
# Step 2: Extract product titles
productTitles: text(selector: ".product-title") {
text # Retrieves all product titles on page
}
}
`;
try {
const response = await fetch(BQL_ENDPOINT, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${API_KEY}`,
},
body: JSON.stringify({ query }),
});
const data = await response.json();
console.log(`Page ${i} Titles:`, data.data.productTitles.text);
} catch (error) {
console.error("Error scraping page:", error);
}
}
}
// Scrape 10 pages efficiently
scrapeMultiplePages(10);
What This Does:
- Loops through multiple pages dynamically.
- Avoids Cloudflare’s rate limits using session persistence.
- Extracts data efficiently from a Cloudflare-protected site.
- Scales scraping with minimal risk of being flagged.
Conclusion
Cloudflare’s advanced bot protection, including IP blocking, TLS fingerprinting, and JavaScript challenges, complicates scraping workflows. While tools like Puppeteer help bypass these defenses, BrowserQL (BQL) simplifies the process further by automating session management, proxy rotation, and JavaScript execution. BQL saves time, boosts efficiency, and streamlines scaling for scraping professionals. Ready to tackle Cloudflare with ease? Discover how BrowserQL can enhance your projects today.