As a company specializing in data extraction, we help clients leverage libraries like Puppeteer and Playwright to perform comprehensive web scraping tasks. One such task that has been gathering interest is travel data extraction. So, how do you use browserless for flight, bus, or hotel data extraction at scale with headless browsers?
We'll walk you through a step-by-step guide using a snippet of code to extract flight data from the 'MakeMyTrip' website, this is for educational purposes only, and highly recommend reading the ToS of each platform before scraping data. Please keep in mind that websites change every so often, so this scraper may not work anymore by the time you read this blogpost, but this is still useful since the steps to get it to work will be the same.
It's worth noting, that each site has different CSS selectors and workflows, so this code proves a great starting point to understand how to use these services.
Steps to extract travel data from a site
Let's divide the task into smaller steps
- Analyze the site you're going to scrape
- Identify if there are anti-bot detecting mechanisms
- Find the CSS selectors you need to extract data from
- Generate code to return the information you need in the desired format
Analyze the site
Looking at their site, we can see they have a form you can fill out with the departure and arrival location, dates, and info of travelers. If we click on the Search button, we can see that the parameters append to the URL and end up like this:
We can thus skip the first step and reverse-engineer the URL format to directly reach the site's result page.
Obstacles
We'll have to see what steps the site requires from us before the data is available. In Make-My-Trip's case, once we load that URL, we can observe there's a popup, which we'll have to close.
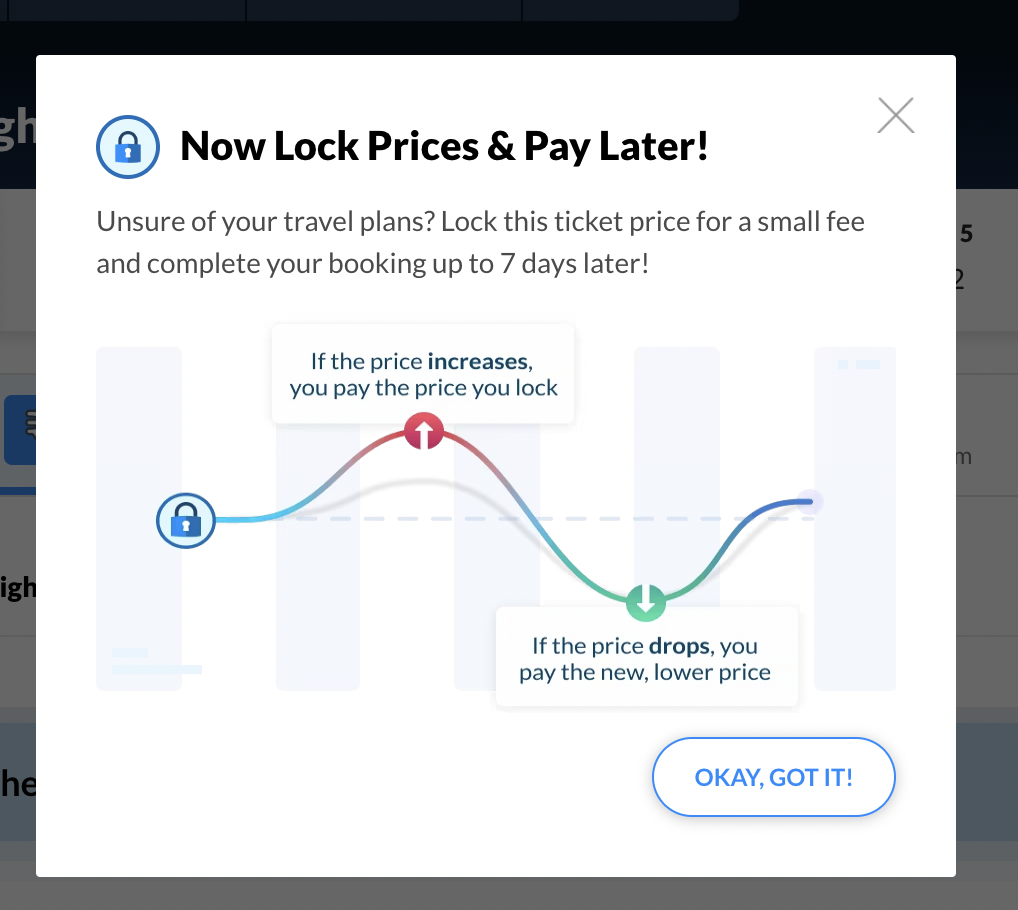
Identify if there are anti-bot detecting mechanisms
There are several mechanisms that sites can have, like checking user agents, javascript challenges, and the more complex ones involving checking IP addresses to not be data centers.
For the first type, using our &stealth flag and &headless=false (headed) flag usually does the trick. The stealth flag injects user-like configuration into the browser and running headed mode will also modify the user agent of the browser to a more user-like value.
If you're getting blocked due to IP Addresses, you'll want to use our residential proxies. In Make-My-Trip, this is the case, so you might get results a few times, but eventually, you'll have to use a residential proxy to get consistent results.
Find the CSS selectors you need to extract data from
To find the CSS selectors, you'll have to use the devtools inspector and find which HTML elements actually have the information you want. If you have CSS knowledge, this should be easy, otherwise, find the element in the devtools inspector and right-click that element, then go to copy -> copy selector.
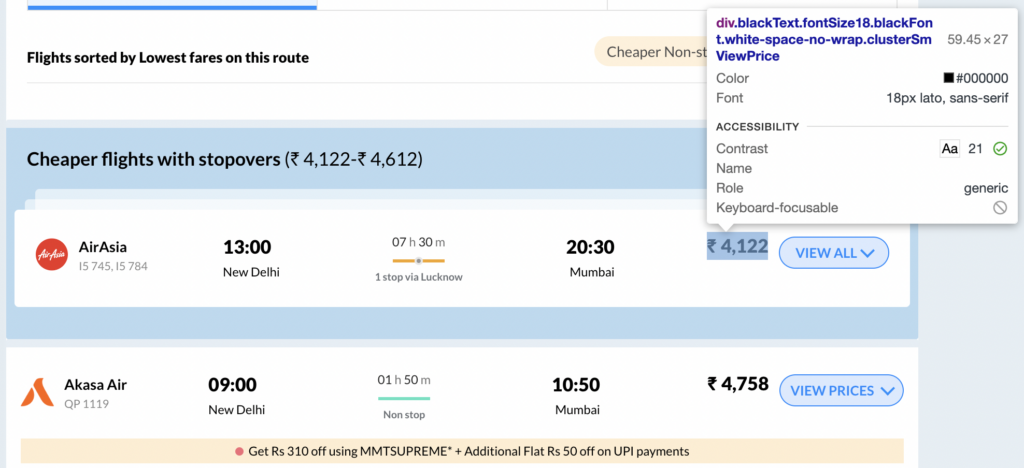
Once you have this CSS selector, you should be good to extract it. In our case, we found 2 selectors, one selector returns the prices of the flights, and the other selector returns metadata about the flights:
Fetch prices:
const prices = [
...document.querySelectorAll(".listingCard .makeFlex.spaceBetween .priceSection"),
];
Fetch information about the flights:
const data = [
...document.querySelectorAll(
".listingCard .makeFlex.spaceBetween .makeFlex .makeFlex div p",
),
];
Return the information you need in the desired format
Once we find these selectors, we'll have to format the information in a structure that's useful for us. Here's the code that will perform all the above actions and output the extracted data.
Code to extract travel data
You can copy and paste this code into our live debugger to see this work in real-time. Alternatively, you can convert this to CJS and wrap this code in our /function API to run this code with one HTTP request or use the Puppeteer library to run this from your app.
export default async ({ page }: { page: Page }) => {
await page.authenticate(
{
username:"your_username",
"password": "your_password"
}
)
await page.goto('https://www.makemytrip.com/flight/search?itinerary=DEL-BOM-04/08/2026&tripType=O&paxType=A-1_C-0_I-0&intl=false&cabinClass=E&ccde=IN&lang=eng'); //Navigate to the site
await page.waitForSelector('.bgProperties.icon20.overlayCrossIcon');//wait for popup to appear
await page.click('.bgProperties.icon20.overlayCrossIcon');//close popup
await page.evaluate(()=>{ //scroll down to trigger all flights to download
document.scrollingElement.scrollBy(0,5000)
});
await page.waitForTimeout(500);//wait to allow the server to send information of the lazy-loaded flights
const items = await page.evaluate(() => {
const prices = [...document.querySelectorAll('.listingCard .makeFlex.spaceBetween .priceSection')]; //find price elements
const data = [...document.querySelectorAll('.listingCard .makeFlex.spaceBetween .makeFlex .makeFlex div p')]; //find additional information elements
var j=-1;
const flightData = data.map((el: HTMLAnchorElement) => {
let text=el.textContent;
console.log(j);
switch(j){
case -1:
j=j+1;
return {airline:text}
break;
case 0:
j=j+1;
return {flightNumber:text}
break;
case 1:
j=j+1;
return {departureTime:text}
break;
case 2:
j=j+1;
return {departureLocation:text}
break;
case 3:
j=j+1;
return {flightDuration:text}
break;
case 4:
j=j+1;
return null
break;
case 5:
j=j+1;
return {stops:text}
break;
case 6:
j=j+1;
return {arrivalTime:text}
break;
case 7:
j=-1;
return {arrivalLocation:text}
break;
}
});
let i=-9;
const results = prices.map((el: HTMLAnchorElement) => {
const myText=el.textContent;
const position=myText.search("per");
const myPrice=myText.slice(0,position);
i=i+9;
return Object.assign({}, {price:myPrice},flightData[i],flightData[i+1],flightData[i+2],flightData[i+3],flightData[i+4],flightData[i+5],flightData[i+6],flightData[i+7],flightData[i+8]);
});
return JSON.stringify(results);
});
return JSON.parse(items);
};
Let's dissect this step by step
The 'page.goto()' function navigates the headless browser to the desired URL, which in this case is a MakeMyTrip flight search results page.
await page.goto(
"https://www.makemytrip.com/flight/search?itinerary=DEL-BOM-28/07/2026&tripType=O&paxType=A-1_C-0_I-0&intl=false&cabinClass=E&ccde=IN&lang=eng",
);
The script waits for a specific popup to appear on the page and then closes it. This ensures a clear page layout for data extraction.
await page.waitForSelector(".bgProperties.icon20.overlayCrossIcon");
await page.click(".bgProperties.icon20.overlayCrossIcon");
The script scrolls down to ensure that all the flight information, which might be lazy-loaded (only loaded when they come into view), is fully loaded.
document.scrollingElement.scrollBy(0,5000) });
await page.waitForTimeout(500);
After scrolling and waiting for the server response, the script identifies and gathers all the necessary flight data. It extracts prices and other flight-related information from the HTML of the webpage.
const items = await page.evaluate(() => {
const prices = [...document.querySelectorAll('.listingCard .makeFlex.spaceBetween .priceSection')];
const data = [...document.querySelectorAll('.listingCard .makeFlex.spaceBetween .makeFlex .makeFlex div p')];
We then map over the extracted data and organize it into relevant categories: airline, flight number, departure time, departure location, flight duration, stops, arrival time, and arrival location. We do the same with the price data.
const flightData = data.map((el: HTMLAnchorElement) => { //giving the flight data structure here... });
const results = prices.map((el: HTMLAnchorElement) => { //giving the price data structure here... });
Lastly, we combine price and flight data into a single Object and return that in a JSON object.
return Object.assign({},
{price:myPrice},flightData[i],flightData[i+1],flightData[i+2],flightData[i+3],flightData[i+4],flightData[i+5],flightData[i+6],flightData[i+7],flightData[i+8]);});
return JSON.stringify(results); });
Finally, we parse the JSON string back into an array of JavaScript objects and return it as the result of the function.
return JSON.parse(items); };
The results of running this code should output the following dataset
const data = [
{
"price": "₹ 4,122VIEW AL",
"airline": "AirAsia",
"flightNumber": "I5 745, I5 784",
"departureTime": "13:00",
"departureLocation": "New Delhi",
"flightDuration": "07 h 30 m ",
"stops": "1 stop via Lucknow",
"arrivalTime": "20:30",
"arrivalLocation": "Mumbai"
},
...
],
Conclusion
Flight data extraction doesn't have to be an uphill battle. By employing the above method on our platform, scraping flight data at scale is simplified, providing you with the necessary details at your fingertips. With Puppeteer, Playwright, and our platform working in unison, flight data extraction has never been easier or more efficient.
This is a great starting point for anyone trying to extract data from flight/hotel/bus reservation websites. Let us know if this was useful and would like more blogposts like this.
Feel free to reach out to support@browserless.io if you have any questions or refer to the official documentation of each library.