Booking.com is a go-to platform for travelers worldwide, offering tons of data on hotels, apartments, and unique stays. For businesses, scraping this data can unlock insights into market trends, competitive pricing, and customer preferences. But Booking.com doesn’t make it easy, as it utilizes advanced anti-bot protections like CAPTCHAs, IP blocks, and dynamic content that can trip up most scraping tools.
Booking.com Page Structure
When scraping Booking.com, understanding how their pages are structured is the first step to getting the most out of your scraping efforts. Their website is packed with valuable details, and knowing where to look will help you extract the right data without wasting time.
Let’s walk through the key pages and the data they offer so you can confidently plan your scraping workflow.
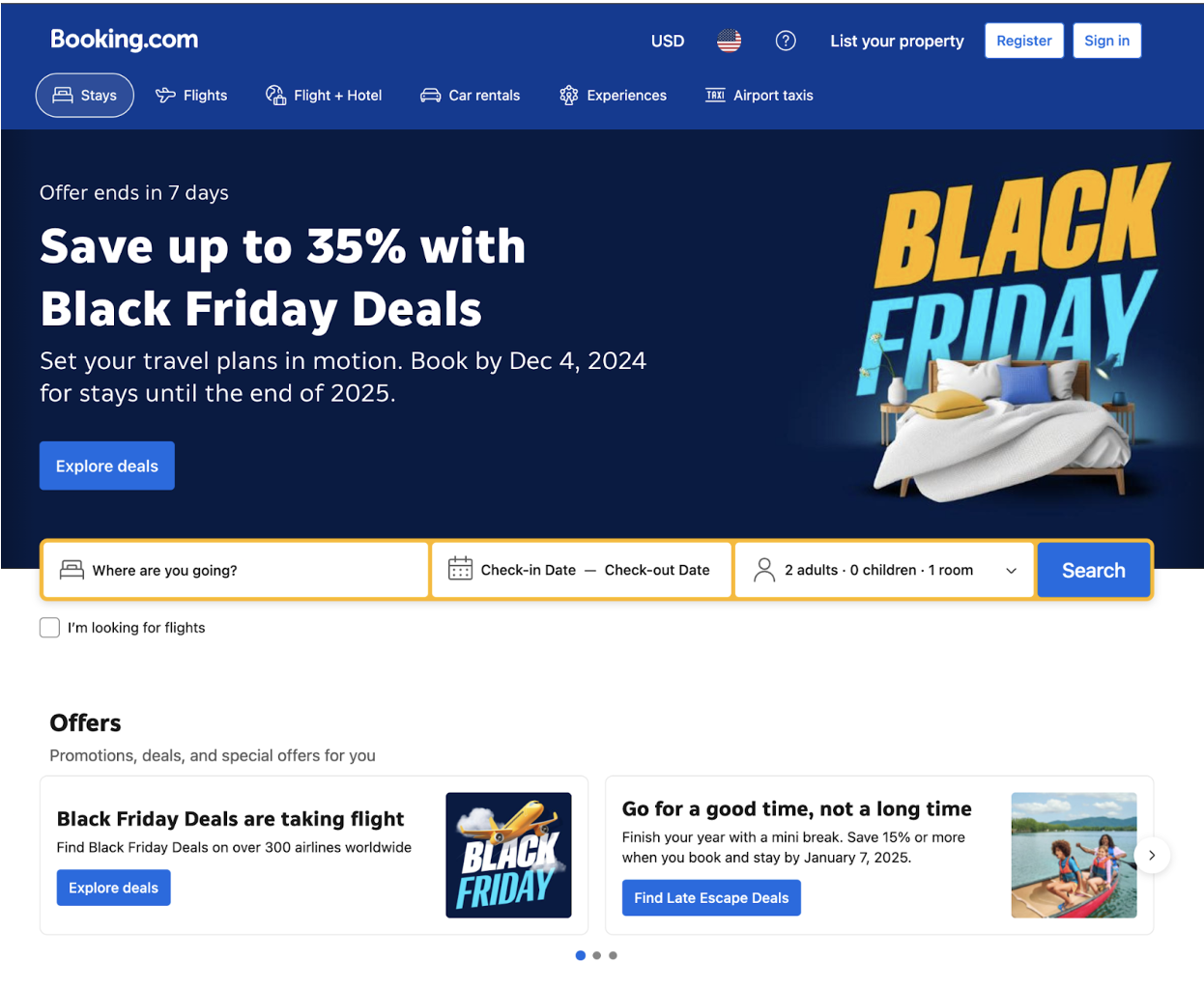
The Home Page is where every search journey starts. It’s clean and simple but includes important elements for automating your scraping tasks.
Here’s what you can focus on:
- Search Bar: The search bar is where users enter their destination, travel dates, and number of guests. For scraping, this is your launchpad. Target these fields to send your automated search queries.
- Promotions and Deals: Booking.com highlights seasonal promotions like Black Friday discounts or last-minute deals. This is a good place to start if you want to track trends or analyze pricing patterns.
This page is the starting point for collecting data, so it's key to set up your scraper to interact with these fields. Once a search is performed, the Listing Page displays all the results.
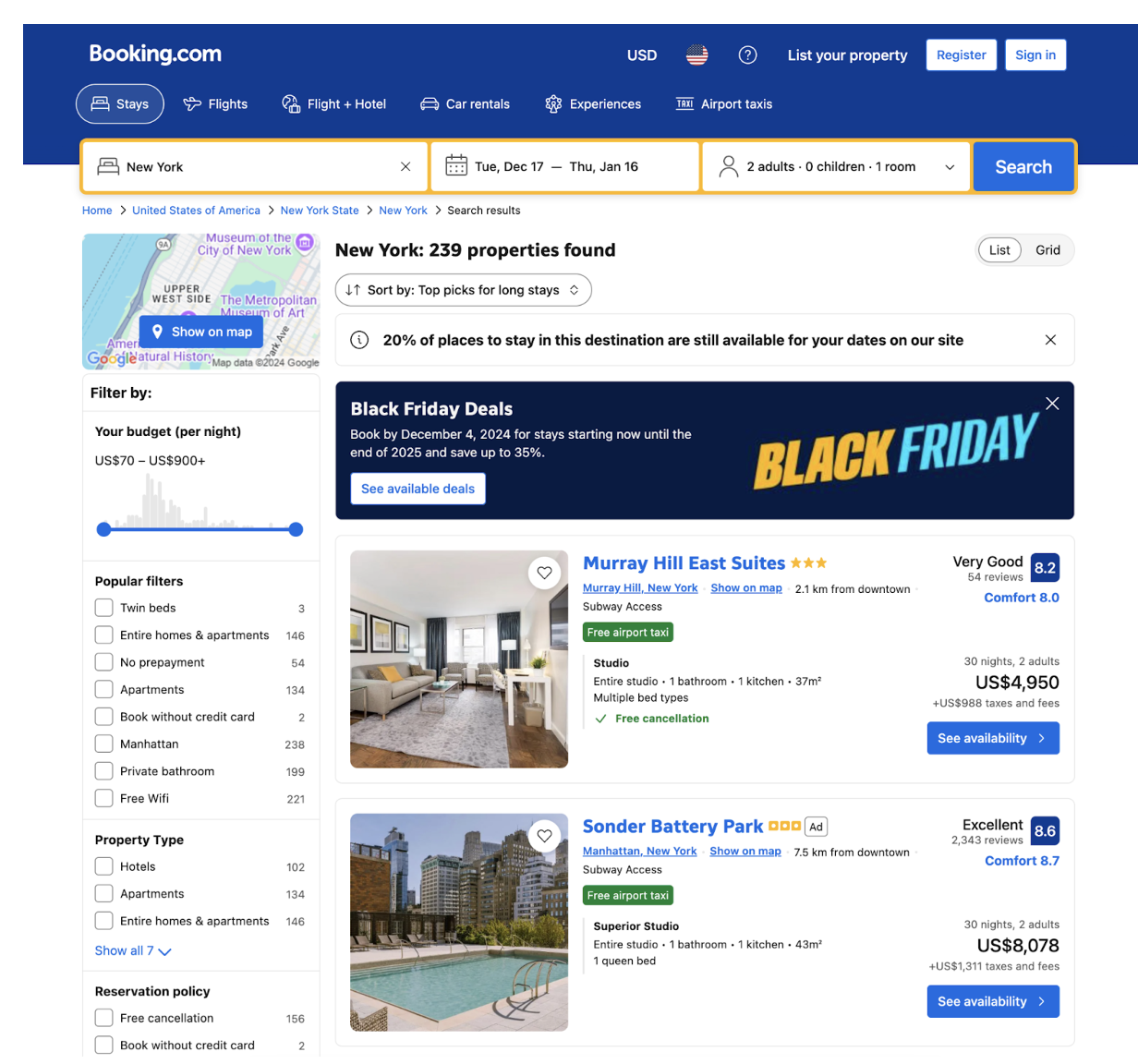
There’s a wealth of data here, including:
- Hotel Names: The property name is front and center in each listing, making it easy to scrape and categorize.
- Prices: You’ll see nightly rates and total costs for various room options. This is especially useful if you’re comparing prices across locations or properties.
- Ratings and Reviews: Each listing shows a star rating and an overall review score. These scores are important to measure customer satisfaction or identify top-rated properties.
- Filters: The sidebar offers filters for budget, property type, amenities, and more. Scraping this can help you understand user preferences and the range of options available.
The listing page is perfect for gathering data across multiple properties, making it a great place to focus if you need bulk information from a specific destination.
When you click on a specific hotel, you’ll land on the Property Details Page, which is a goldmine of detailed information.
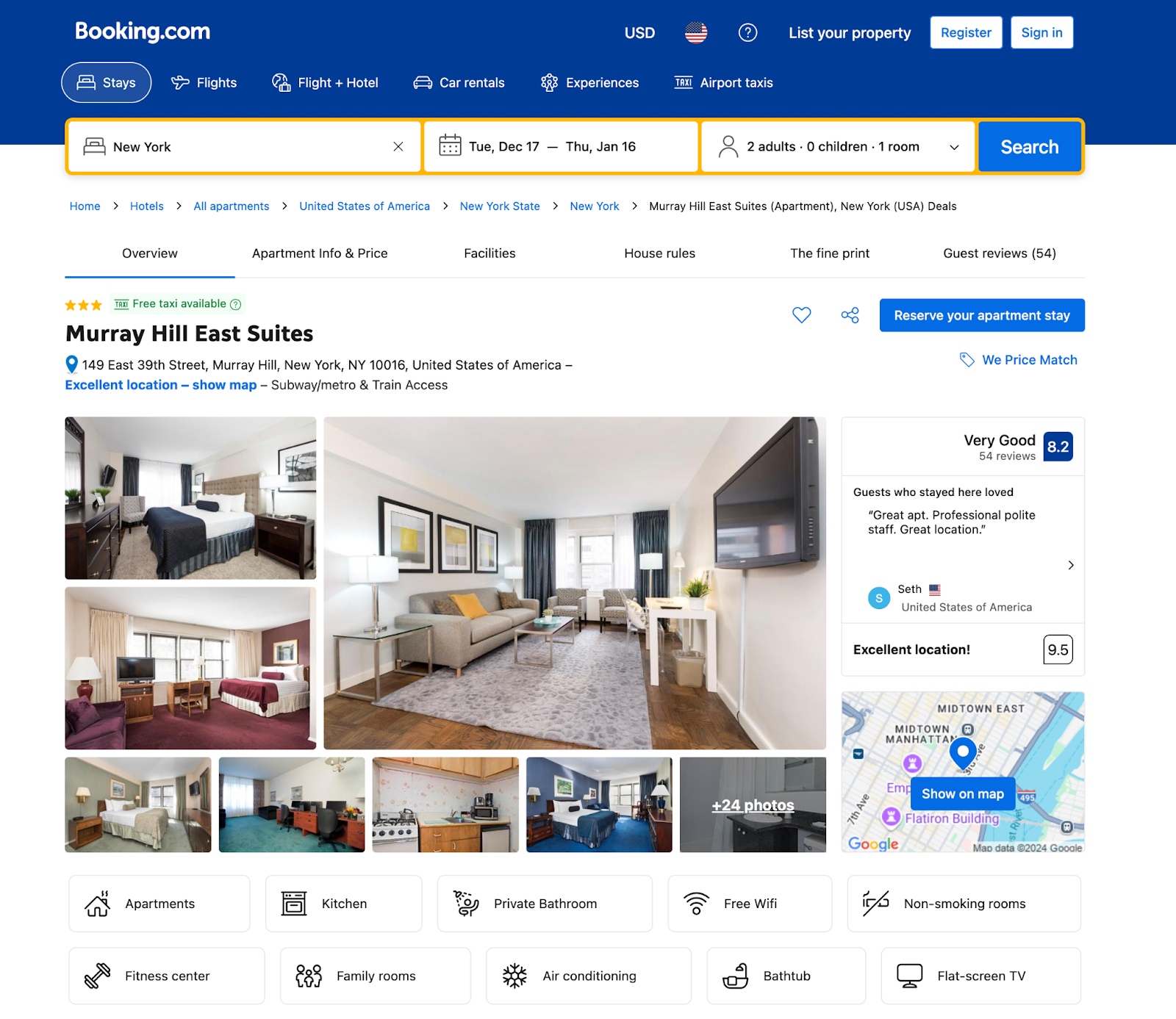
This page is ideal if you’re looking for in-depth data about individual listings. Here’s what you can scrape:
- Amenities: Details like free Wi-Fi, air conditioning, or pet-friendly policies are usually listed here, giving you insights into what properties offer.
- Room Types and Pricing: You’ll find detailed breakdowns of room types, nightly rates, and even availability for specific dates. This is key if you’re analyzing pricing trends.
- Customer Reviews: Beyond the star rating, you can scrape individual reviews to understand what guests say about their experience. This can be useful for sentiment analysis or identifying common complaints.
- Location: Each listing provides the property’s full address and a map view. This data is great for geolocation-based analysis, like identifying hotel density in certain neighborhoods.
The details page contains all the necessary information, making it the perfect stop for building a more focused dataset.
Setting Up Puppeteer for Small-Scale Scraping
If you’re looking to scrape Booking.com for a small project, Puppeteer is a great tool to get started. While it has limitations for large-scale tasks, it’s perfect for experimenting or collecting data from a few pages.
Let’s walk through a script that searches for hotels in Tokyo and extracts hotel names and locations into a CSV file.
1. Installing Puppeteer
Before getting started, ensure you have Node.js installed. You’ll also need to be familiar with JavaScript and running commands in your terminal. Once you're ready, open your terminal, navigate to your project directory, and install Puppeteer with:
npm install puppeteer
This installs Puppeteer and all the dependencies you need to control a browser with code.
2. Writing a Puppeteer Script for Booking.com
Start by launching Puppeteer and opening Booking.com. Here’s the snippet:
const puppeteer = require("puppeteer");
(async () => {
const browser = await puppeteer.launch({ headless: false }); // Run with a visible browser for debugging
const page = await browser.newPage();
// Navigate to Booking.com
await page.goto("https://www.booking.com", { waitUntil: "domcontentloaded" });
// More steps will go here...
})();
This script initializes Puppeteer, launches a browser and navigates to Booking.com. Notice the headless: false setting lets you see what the browser is doing, which is super handy when testing.
Pop-ups are a common hurdle when scraping websites. Booking.com might show a cookie consent banner or a sign-in modal, which can interrupt the flow of your script. To handle this, we include logic to detect and dismiss these pop-ups. The retry mechanism ensures we don’t miss any stubborn pop-ups.
// Function to close pop-ups with retry mechanism
async function closePopups(retries = 3) {
const popupSelectors = [
'button[aria-label="Dismiss sign-in info."]', // Sign-in popup
"#onetrust-accept-btn-handler", // Cookie banner
];
for (let attempt = 0; attempt < retries; attempt++) {
console.log(`Attempt ${attempt + 1} to close pop-ups...`);
let popupsClosed = false;
for (const selector of popupSelectors) {
try {
if (await page.$(selector)) {
await page.click(selector);
console.log(`Pop-up dismissed: ${selector}`);
popupsClosed = true;
}
} catch (err) {
console.log(`Error dismissing pop-up for selector: ${selector}`);
}
}
if (!popupsClosed) break; // Exit loop if no popups detected in this attempt
await page.waitForTimeout(1000); // Wait briefly before retrying
}
}
// Call the pop-up handler
await closePopups();
Here’s what’s happening:
- Selectors: The
popupSelectorsarray holds the CSS selectors for the pop-ups we expect. - Retries: If the pop-ups don’t show up immediately, the function retries up to three times.
- Dismiss Logic: The await
page.click(selector)dismisses the pop-ups if they’re found.
Next, we interact with the search bar to find hotels in Tokyo. The puppeteer types "Tokyo, Japan" into the input field and simulates pressing Enter.
const searchInputSelector = 'input[name="ss"]';
console.log("Focusing on the location input...");
await page.click(searchInputSelector);
await page.type(searchInputSelector, "Tokyo, Japan", { delay: 100 });
console.log("Pressing Enter to submit the form...");
await page.keyboard.press("Enter");
// Wait for the results page to load
const resultsContainerSelector = "[data-results-container]";
console.log("Waiting for the search results container to load...");
await page.waitForSelector(resultsContainerSelector, { timeout: 15000 });
What's Happening?
- Focus and Type: The script locates the input field by its name attribute (
ss) and types the location with a slight delay for a natural effect. - Submit the Form: The script simulates pressing Enter to initiate the search.
Wait for Results: The script waits for the results container to load, ensuring the next steps run smoothly.
Once the results page loads, we extract hotel names and locations using Puppeteer’s $$eval function. This runs a function in the page context to collect the data.
const propertyCardSelector = '[data-testid="property-card"]';
const hotelData = await page.$$eval(
propertyCardSelector,
(cards) =>
cards
.map((card) => {
const titleElement = card.querySelector('[data-testid="title"]');
const name = titleElement ? titleElement.textContent.trim() : null;
const locationElement = card.querySelector('[data-testid="address"]');
const location = locationElement ? locationElement.textContent.trim() : null;
return { name, location };
})
.filter((hotel) => hotel.name), // Filter out items without names
);
console.log("Hotel Data Extracted:", hotelData);
What’s happening?
- Select Cards: Each hotel’s data is inside an element with the
data-testid="property-card"attribute. - Extract Name and Location: For each card, the script grabs the name and location using their respective attributes
(data-testid="title" and data-testid="address"). - Filter Valid Results: Only include hotels that have a name.
3. Saving the Results to a CSV File
To save the extracted data, we convert it into CSV format and write it to a file using the json2csv library and Node.js’s fs module.
const fs = require("fs");
const path = require("path");
const { parse } = require("json2csv");
// Convert hotel data to CSV
const csv = parse(hotelData, { fields: ["name", "location"] });
// Write the CSV data to a file
const filePath = path.join(__dirname, "hotel_data.csv");
fs.writeFileSync(filePath, csv, "utf8");
console.log(`Hotel data saved to ${filePath}`);
What's Happening?
- Convert to CSV: The
json2csvlibrary converts the hotel data into CSV format with headers fornameandlocation. - Save to File: The
fs.writeFileSyncfunction writes the CSV data to a file named hotel_data.csv in the current directory.
4. Running the Script
To run the script, save it as scrape-bookingcom.js.
Run it in your terminal with:
node scrape-bookingcom.js
Once it finishes, you’ll find hotel_data.csv in your project directory.
This script is a solid starting point for small-scale projects, but let’s be honest: handling things like pop-ups, retries, and dynamic content can get tedious fast. While it’s great to learn how all the pieces work together, managing these challenges manually in a script can feel like reinventing the wheel.
If you’re finding this process time-consuming or cumbersome, consider a specialized tool that handles these complexities for you, offering built-in solutions for scraping, data extraction, and seamlessly dealing with dynamic web content.
When Traditional Scraping Tools Fall Short

Limitations of Puppeteer with Stealth Libraries
Tools like Puppeteer are widely used for web scraping but often fall short of Booking.com. These libraries are designed to provide complete control over the browser, which is great for general automation but not for avoiding detection.
Booking.com’s anti-bot systems are highly advanced, monitoring for signs like unnatural browsing behavior, automation-specific headers, and repeated browser fingerprints.
Even with stealth plugins, these tools leave detectable traces. Booking.com’s systems have become adept at identifying bots, analyzing patterns like consistent interaction timings, or the absence of typical human browsing randomness.
While Puppeteer might work for small projects, scraping Booking.com at scale becomes challenging with constant CAPTCHA interruptions, IP blocks, and flagged activity.
Limitations When Scaling Up
While Puppeteer works well for smaller tasks, scraping Booking.com at scale introduces several challenges.
Booking.com has advanced anti-bot systems that become more aggressive as your request volume increases. These include CAPTCHAs, IP blocking, and dynamic content that loads differently for automated requests. As you scale up, these defenses make it increasingly difficult to scrape consistently.
Even with stealth plugins or rotating proxies, Booking.com’s systems can detect patterns typical of bots, such as identical browsing behaviors, repeated IP usage, or predictable interaction timings. Over time, you’ll encounter more CAPTCHAs and blocked access, which makes Puppeteer unsuitable for large-scale scraping without additional tools.
Getting Started with BrowserQL
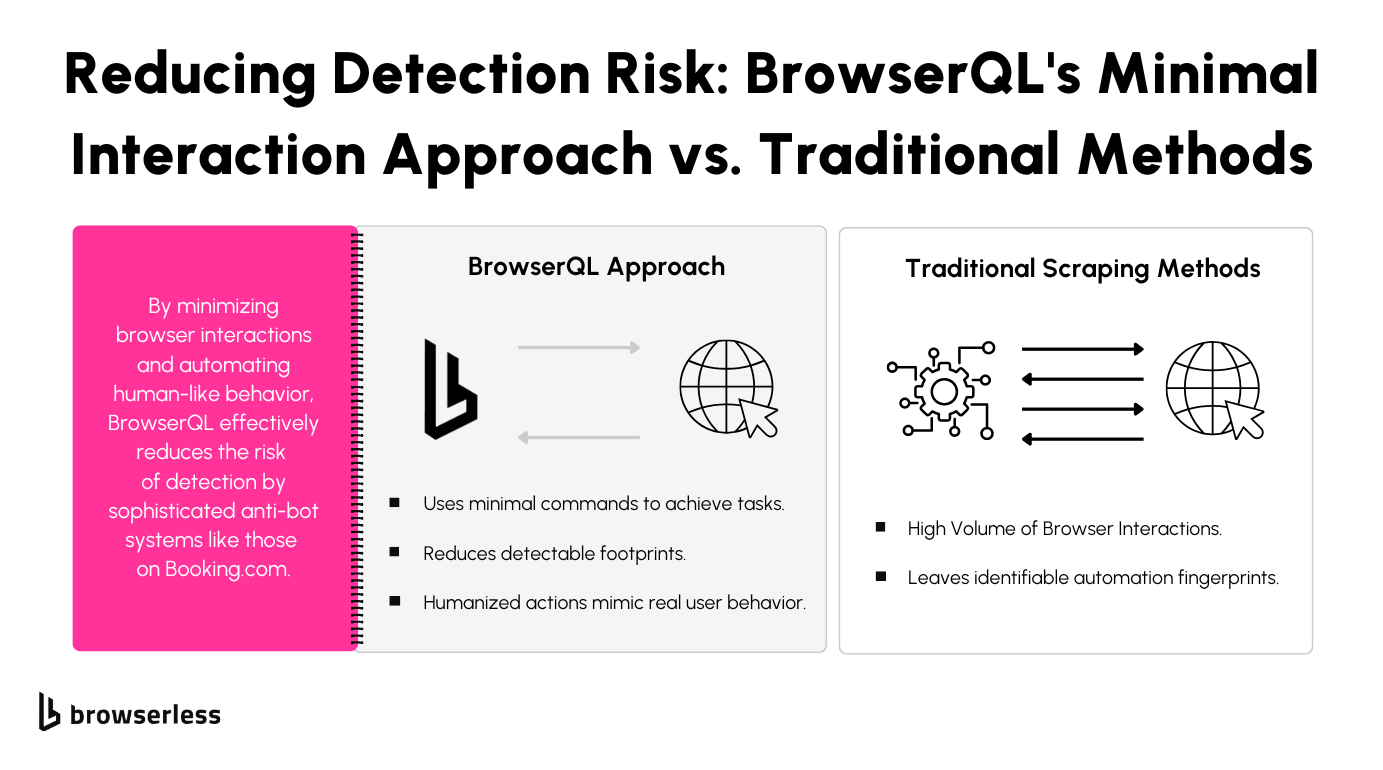
BrowserQL is a modern scraping tool designed specifically to handle the challenges of advanced bot detection systems. It uses GraphQL-based commands to directly control the browser via Chrome DevTools Protocol (CDP).
This means you can interact with the browser highly efficiently, avoiding the detectable behaviors that more traditional tools like Puppeteer often leave behind.
What makes BrowserQL stand out for scraping Booking.com is its ability to mimic human-like interactions immediately.
It automatically includes features like realistic typing, scrolling, and waiting, which make your scraping efforts look like they’re coming from an actual user.
How BrowserQL Avoids Booking.com Bot Detection
One major challenge when scraping Booking.com is avoiding detection by anti-bot systems. BrowserQL addresses this by keeping browser interactions as undetectable as possible. It avoids the common signs of automation, like unusual headers or over-reliance on specific commands, so your activity blends seamlessly with legitimate user traffic.
Booking.com monitors for behaviors that don’t look like real users, such as too-fast scrolling or uniform clicking patterns. BrowserQL takes care of this by adding natural delays between actions, realistic mouse movements, and smooth scrolling. This helps your scraping scripts operate under the radar without additional coding on your part.
For tougher environments where bot detection goes deeper, BrowserQL can run on real consumer hardware. This feature provides genuine device characteristics, like authentic GPU data and hardware fingerprints, making it almost impossible for Booking.com’s detection systems to distinguish your script from a human user. This feature is especially helpful for enterprise-level scraping.
Setting Up BrowserQL
Getting started with BrowserQL is simple. After creating an account with Browserless, head to your account page and download the BrowserQL IDE. Once downloaded, follow the quick installation steps to set up the IDE on your system. With the IDE ready to go, you’ll have all the tools needed to write, test, and refine your scripts in one place.
BrowserQL offers a free trial to help you get familiar with its capabilities. Signing up is quick, and the trial includes everything you need to get started—full access to the BrowserQL IDE and its features. Once you’re set-up, you can begin building and running scripts for scraping Booking.com without any upfront commitment. Visit the Browserless website to sign up and start exploring.
Guide to Scraping Booking.com with BrowserQL
Scraping Booking.com can seem like a challenging task, but with BrowserQL, it becomes a structured and manageable process. Here’s how you can use BrowserQL to extract data efficiently, with a detailed breakdown of the steps.
1. Setting Up Your First BrowserQL Script
Before extracting data, the first step is to load the Booking.com homepage. This ensures we start with a clean slate and allows us to verify that everything is loading as expected.
Here’s the mutation that loads the page:
goto(url: "https://www.booking.com", waitUntil: networkIdle) {
status
time
}
This goto command tells the browser to navigate to the specified URL and wait until the network activity has settled (networkIdle). The status and time returned help you confirm that the page loaded successfully and quickly.
2. Handling Popups (Nobody Likes Interruptions!)
Booking.com sometimes displays a modal popup encouraging users to sign in for discounts. This modal could block interactions, so we’ll handle it by checking for its existence and clicking the close button if it appears.
Here’s how we handle the modal popup:
closeModal: click(
selector: "button[aria-label='Dismiss sign-in info.']",
visible: true,
timeout: 5000
) {
time
}
This snippet does two things:
- Checks for the modal popup: Using the
timeoutparameter, we wait up to 5 seconds for the popup to appear. - Closes the modal: The
clickcommand interacts with the close button if the popup exists.
Doing this ensures the popup doesn’t prevent our script from progressing.
3. Performing a Search
Next, we input “New York” into the search bar to specify our destination. The type command mimics human typing, making it look natural to avoid detection.
type(
text: "New York",
selector: "input[name='ss'][placeholder='Where are you going?']",
delay: [1, 10]
) {
selector
}
The delay parameter adds a random pause between keystrokes, making the interaction more human-like.
Once we’ve entered our destination, it’s time to hit “Search.” The click command submits the search form:
submitSearch: click(
selector: "button[type='submit'][class*='a83ed08757']",
visible: true
) {
selector
time
}
This tells the browser to find the search button (using a refined selector) and simulate a click.
4. Waiting for Results to Load
After submitting the search, we need to ensure the results page fully loads before extracting data. Here’s how we handle this:
waitForSelector(
selector: "div[data-testid='property-card']",
timeout: 15000
) {
time
selector
}
The waitForSelector command pauses the script until the search results are displayed (or until the timeout is reached). This ensures we’re working with a fully loaded page.
5. Extracting Hotel Data
Now for the fun part—grabbing the data! With the page loaded, we extract information about hotels, such as names, prices, and locations:
htmlContent: html(
visible:false
) {
html
}
This grabs the entire HTML content of the results page, which we’ll parse later using a library like cheerio in Node.js.
6. Parsing and Saving Data
Once we’ve extracted the HTML, we parse it to find the specific data we’re interested in. For this, we use the cheerio library, which makes it easy to work with HTML in JavaScript.
Here’s an example of how we parse hotel data:
const $ = cheerio.load(html);
const properties = [];
$('div[data-testid="property-card"]').each((index, element) => {
const title = $(element).find('span[data-testid="title"]').text().trim();
const price = $(element)
.find('span[data-testid="price-and-discounted-price"]')
.text()
.trim();
const location = $(element).find('span[data-testid="address"]').text().trim();
properties.push({ title, price, location });
});
This code loops through each hotel card on the results page and extracts its title, price, and location. The result is an array of objects that looks like this:
[
{
title: "Beautiful Hotel",
price: "$150",
location: "Downtown, New York",
},
{
title: "Luxury Stay",
price: "$200",
location: "Midtown, New York",
},
];
Finally, we save this data to a CSV file for easy access later:
const csvWriter = createObjectCsvWriter({
path: "booking_results.csv",
header: [
{ id: "title", title: "Title" },
{ id: "price", title: "Price" },
{ id: "location", title: "Location" },
],
});
await csvWriter.writeRecords(properties);
7. Exporting Your Script to cURL
Once your script works, you can easily export it to cURL to run it from the terminal or integrate it into other workflows. Here’s an example:
curl --request POST \
--url 'https://production-sfo.browserless.io/chromium/bql?token=YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"query": "mutation SearchBookingWithModalHandling { ... }",
"variables": {},
"operationName": "SearchBookingWithModalHandling"
}'
This command sends the BrowserQL query to the Browserless API and executes it. You’ll get the HTML response directly in your terminal or script.
Note: Websites like Booking.com frequently update their structure, so verifying the CSS selectors or IDs used in your script before running it is essential.
Conclusion
Scraping Booking.com doesn’t have to be complicated. BrowserQL makes it much easier by overcoming modern detection systems and letting you scrape efficiently. Whether you’re analyzing competitors or gathering market insights, BrowserQL has the tools to do it. Try it out with a free trial to see how it can enhance your scraping projects.
FAQs
**Is it legal to scrape data from Booking.com? **Scraping publicly available data is usually okay, but you should review Booking.com’s terms of service and consult legal experts to stay compliant.
**How does BrowserQL differ from Puppeteer and Playwright? **BrowserQL is built for stealth, avoiding detection with realistic human-like actions like typing, scrolling, and minimal technical fingerprints.
**Can I use BrowserQL with my existing scraping projects? **Yes, BrowserQL scripts work seamlessly with other tools and tech stacks, making integration simple.
**What if BrowserQL doesn’t bypass Booking.com’s bot detection? **Browserless offers support to help troubleshoot and adapt your scripts as detection systems evolve.
**How do I get started with BrowserQL? **Sign up for a free trial on our website, download the IDE, and start building your scripts in minutes!