Introduction
You’re probably trying to scrape agent leads from Zillow to build your outreach or analyze the competition. Zillow is packed with useful data on agents, including contact numbers, reviews, sales stats, and more, making it a top resource for real estate professionals.
However, scraping Zillow can be challenging due to CAPTCHAs, IP blocks, and dynamic content. This guide will teach you how to extract agent contact numbers from Zillow effectively.
Zillow Agent Page Structure
When scraping Zillow for agent data, it’s important to understand how the website organizes its information. Zillow’s agent pages provide detailed insights into real estate agents, making them invaluable for market analysis and lead generation.
Let’s break down the key elements of the structure.
Agent Listing Page
The Agent Listing Page allows users to browse and search for real estate agents in a specific location.
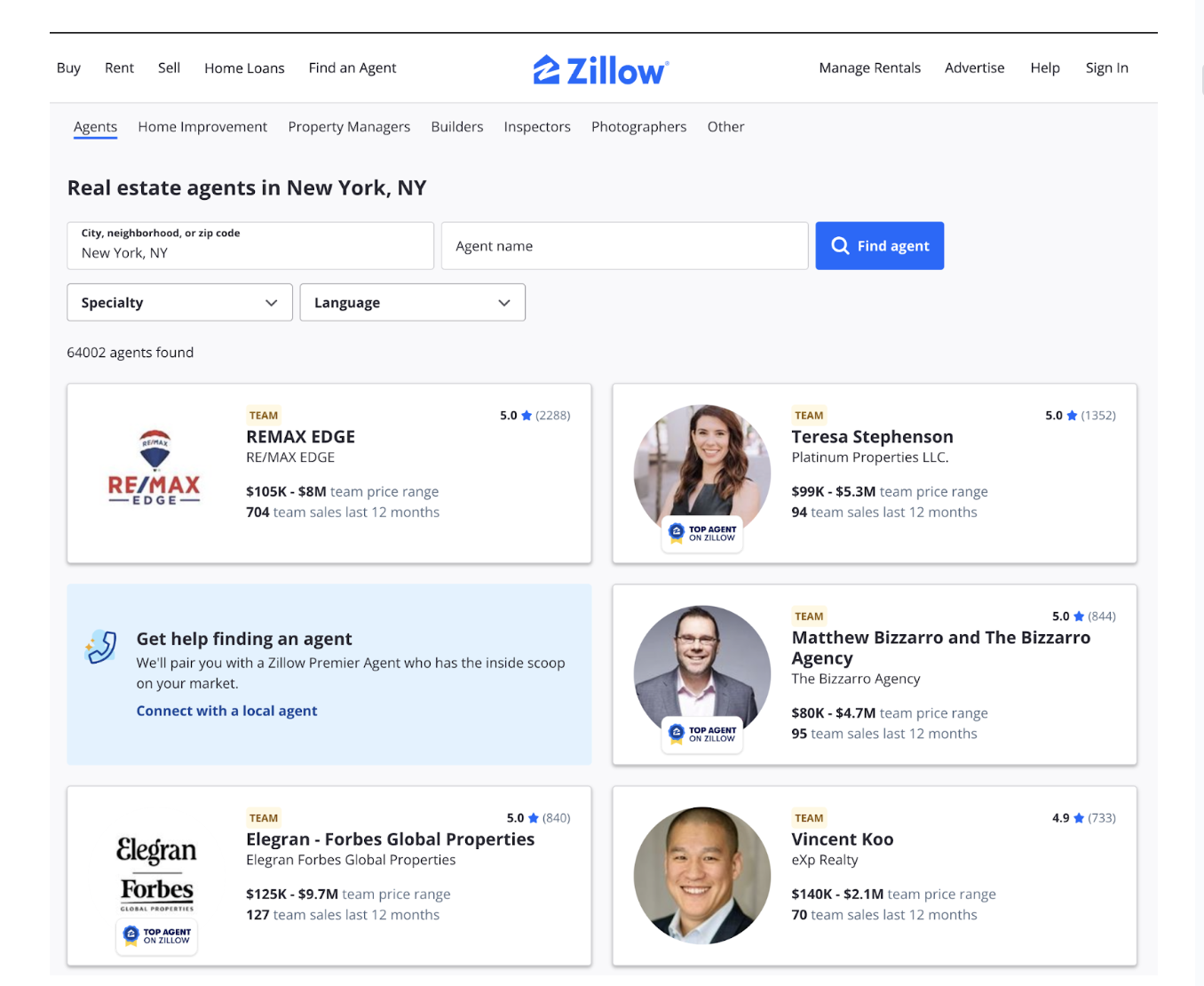
For example, the page above shows New York, NY agents. This page contains key data points for each agent, including:
- Agent Name: Displayed prominently to identify the agent or team.
- Ratings and Reviews: The number of reviews and an overall star rating (e.g., "5.0 ★").
- Price Range: The range of property prices the agent typically handles (e.g., "$105K–$8M").
- Sales Data: Metrics such as the number of sales in the last 12 months, giving insights into their activity level.
This page is your starting point for gathering agent data and offers a snapshot of each agent’s profile.
Individual Agent Page
Clicking on an agent’s name leads to their Individual Agent Page, which provides more detailed information about their work and contact details.
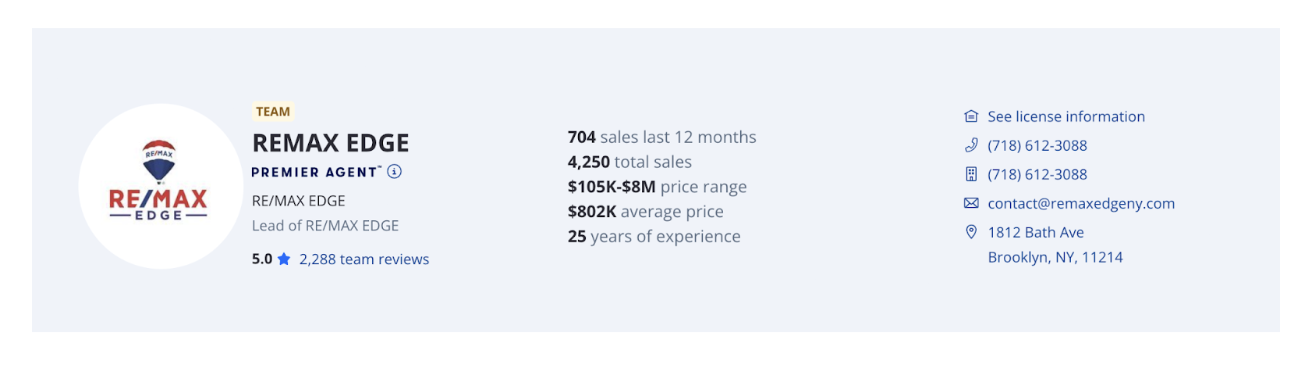
This page includes:
- Agent Name and Team Information: The name of the agent or team, along with their affiliation (e.g., "RE/MAX Edge").
- Contact Details: Phone numbers, email addresses, and office addresses, making it easy to gather lead information.
- Sales and Experience: Metrics include total sales, sales in the past year, average property price, and years of experience.
- Customer Reviews: Testimonials and feedback from previous clients.
- Licensing Information: Details about the agent’s licensing, which may be useful for compliance.
This page is particularly useful for lead generation and contains direct contact details.
Why Traditional Scraping Tools Fall Short
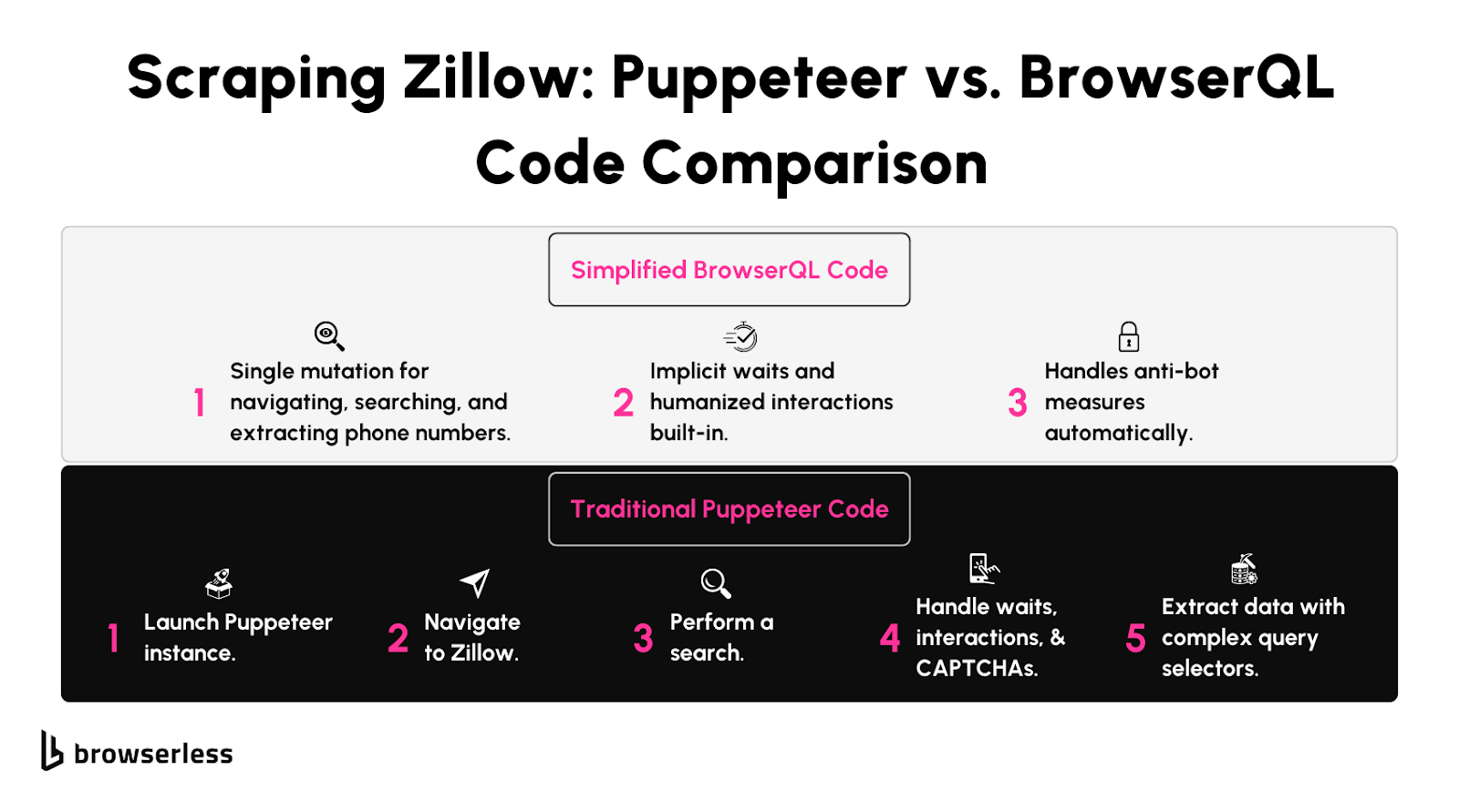
Limitations of Puppeteer with Stealth Libraries
Scraping Zillow might seem straightforward with tools like Puppeteer, especially if you’re working on a small scraping project. They’re great for loading property pages, extracting basic data, and handling JavaScript-rendered content.
But as soon as you try scaling up, like pulling data across multiple cities or thousands of agent profiles, you’ll likely hit some roadblocks like this:

Zillow has advanced systems in place to detect bots. When sending requests, these systems can detect repetitive behaviors, like identical browser fingerprints or patterns.
Even if you use stealth plugins or proxies, these tools can leave subtle traces, like how they handle headers or scripts. Zillow’s anti-bot defenses are designed to catch these patterns, often resulting in CAPTCHAs, blocked requests, or temporary bans.
The Need for Specialized Scraping Tools
When collecting data at scale on Zillow, you need a tool built for the job. That’s where BrowserQL shines. It’s designed to handle modern anti-bot systems and works seamlessly with Zillow’s complex defenses.
What makes BrowserQL different is how naturally it behaves. It skips unnecessary actions that can reveal automation and focus on realistic interactions.
It can simulate typing into search fields, scrolling through listings, and even mouse movements like a real person. This helps you avoid detection and makes collecting Zillow’s data easier and more reliable, even on larger projects.
How BrowserQL Avoids Zillow’s Anti-Bot Detection

Traditional libraries like Puppeteer often leave detectable patterns, such as repetitive requests or standard headers, which anti-bot systems can flag. BrowserQL avoids these issues by interacting minimally and intelligently with the browser.
BrowserQL automatically incorporates human-like actions such as realistic typing and mouse movements. For example, searching for properties in Zillow feels more authentic to detection systems because BrowserQL naturally scrolls and delays interactions.
Some detection systems verify hardware attributes like GPU or physical device characteristics. BrowserQL supports running on real hardware, enhancing authenticity for scraping efforts that face stricter anti-bot measures.
Getting Started with BrowserQL
Setting Up BrowserQL
Getting started with BrowserQL is straightforward. First, sign up for a Browserless account and access the BrowserQL IDE download link from your dashboard.
Once downloaded, follow the installation instructions for your operating system. The IDE gives you everything you need to write and execute scripts efficiently.
Part 1: Getting The Agent URLs from Zillow
When scraping Zillow for agent contact details, the first step is gathering a list of agent profile URLs. These URLs direct you to individual agent pages where juicy data like phone numbers and reviews are stored.
Zillow organizes agent profiles by city, making it easier to target specific locations. Let’s walk through how to extract these URLs step-by-step.
Before diving into the scraping process, we need to set up the tools we’ll use. This script relies on three key libraries: node-fetch, cheerio, and csv-writer. These handle everything from making web requests to parsing HTML and saving the results.
import fetch from "node-fetch";
import * as cheerio from "cheerio";
import { createObjectCsvWriter } from "csv-writer";
// Constants
const BROWSERQL_URL = "https://production-sfo.browserless.io/chromium/bql";
const TOKEN = "your_api_token"; // Replace with your BrowserQL API token
const OUTPUT_CSV_PATH = "agent_urls.csv"; // CSV file to store profile URLs
What’s Happening?
node-fetchis making API requests for us.cheeriohelps us sift through webpage content to find what we need.CSV-writersaves our data in an easy-to-read CSV format.
The constants define key details like the BrowserQL API endpoint, our personal API token, and the file path for the output. These constants are like the foundation of our script; changing them lets us tweak the behavior without diving into the code later.
Next, we need to tell the script where to look. For this example, we’re targeting the Los Angeles directory of real estate agents on Zillow. If you want data from a different city, all you need to do is swap out the URL.
// Hardcoded Zillow directory URL
const directoryUrl =
"https://www.zillow.com/professionals/real-estate-agent-reviews/los-angeles-ca/";
**What’s Happening? **This URL leads to a page listing agents in Los Angeles. Zillow organizes these pages by city and state, following a predictable pattern like:
https://www.zillow.com/professionals/real-estate-agent-reviews/{cityname}-{state full name}-{state short code}/
So, if you want agents from Brooklyn, New York, for example, you’d use:
https://www.zillow.com/professionals/real-estate-agent-reviews/brooklyn-new-york-ny/
Now that we know where to go, we need to craft a set of instructions for ByBrowserQLpassQE. This query tells BrowserQL to visit the directory page, wait for it to load fully, and then return the HTML content.
// BrowserQL Query for scraping the directory page
const query = `
mutation ScrapeDirectory {
goto(url: "${directoryUrl}", waitUntil: networkIdle) {
status
time
}
htmlContent: html(visible: false) {
html
}
}
`;
What’s Happening?
goto: This command instructs BrowserQL to navigate to the given URL and wait until there’s no more network activity (this ensures all content is loaded).htmlContent: After the page loads, this part grabs all the HTML content, like taking a snapshot of the webpage’s insides.
This is where the magic begins. We send the query to BrowserQL’s API and wait for it to fetch the webpage’s content.
(async () => {
console.log(`Scraping: ${directoryUrl}`);
// Send the BrowserQL request
const response = await fetch(`${BROWSERQL_URL}?token=${TOKEN}`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ query }),
});
const data = await response.json();
const html = data?.data?.htmlContent?.html;
if (!html) {
console.error(`Failed to scrape ${directoryUrl}`);
return;
}
What’s Happening?
- We use
fetchto send the query to the BrowserQL API, including our API token for authentication. - The response comes back as JSON, and we extract the HTML content from it.
- If something goes wrong—like the page doesn’t load or the query fails—we log an error and stop.
With the HTML in hand, it’s time to sift through it and find all the agent profile links. This is where Cheerio comes in, acting as our HTML detective.
// Load HTML with Cheerio and extract profile URLs
const $ = cheerio.load(html);
const urls = [];
$("a[href^='/profile/']").each((_, element) => {
const relativeUrl = $(element).attr("href");
if (relativeUrl) {
urls.push(`https://www.zillow.com${relativeUrl}`);
}
});
console.log(`Found ${urls.length} profile URLs`);
What’s Happening?
- Cheerio loads the HTML content, making it easy to navigate and search through.
- The selector
a[href^='/profile/']finds all links that point to agent profiles, since these always start with/profile/. - Each relative link is converted to a full URL by adding the base Zillow URL.
Finally, we save the collected profile URLs into a CSV file. This file is a neat and organized way to store the data for further use.
// Write profile URLs to a CSV file
const csvWriter = createObjectCsvWriter({
path: OUTPUT_CSV_PATH,
header: [{ id: "url", title: "Profile URL" }],
});
await csvWriter.writeRecords(urls.map((url) => ({ url })));
console.log(`Profile URLs saved to ${OUTPUT_CSV_PATH}`);
})();
What’s Happening?
- We use
csv-writerto create a CSV file with a single column calledProfile URL. - The list of URLs is formatted into rows, each containing one URL.
- The file is saved to
agent_urls.csv, ready for further analysis or scraping.
Part 2: Getting the Agent Names and Phone Numbers
Now that we’ve successfully gathered the agent profile URLs, it’s time to pull useful data from those pages. This part aims to extract agent names and phone numbers from Zillow profile pages. We’ll use the URLs we saved earlier, fetch the HTML content for each profile, parse it for the required details, and save everything in a structured CSV file for future use.
We begin by importing the required libraries and defining the paths to the input and output CSV files. This ensures our script has the tools it needs and knows where to read and write data.
import fetch from "node-fetch"; // For API requests
import csvParser from "csv-parser"; // To read URLs from the input CSV
import fs from "fs"; // To handle file operations
import createCsvWriter from "csv-writer"; // To write parsed data into a new CSV file
// Define file paths for input and output CSVs
const inputCsv = "agent_urls.csv"; // Input file with URLs
const outputCsv = "parsed_output.csv"; // Output file for parsed data
node-fetch: Used to send API requests to BrowserQL for fetching HTML content.csv-parser: Reads URLs from the input CSV file where we previously stored the agent profile URLs.fs: Handles file reading and writing operations.csv-writer: Writes the extracted agent names and phone numbers into an output CSV file.
We specify the BrowserQL API endpoint and include the authentication token to authorize requests. This step enables our script to communicate seamlessly with the BrowserQL service.
// BrowserQL API endpoint and token
const browserQLUrl =
"https://production-sfo.browserless.io/chromium/bql?token=put_your__api_token_here&proxy=residential&proxySticky=true&proxyCountry=us&humanlike=true&blockAds=true";
- API Endpoint: Points the script to the BrowserQL service where we’ll fetch HTML content.
- Token: Provides authentication for secure access to BrowserQL. It ensures only authorized users can make requests.
Next, we create a function to read the agent profile URLs from the input CSV file. The function ensures that the script processes only the valid URLs stored under the Profile URL column.
const readAgentUrls = async (filePath) => {
const urls = []; // Array to store URLs
return new Promise((resolve, reject) => {
fs.createReadStream(filePath)
.pipe(csvParser()) // Parse the CSV file
.on("data", (row) => {
if (row["Profile URL"]) urls.push(row["Profile URL"]); // Collect valid URLs
})
.on("end", () => resolve(urls)) // Resolve the promise once done
.on("error", (error) => reject(error)); // Handle errors
});
};
- Read the CSV file: Opens the
agent_urls.csvfile and processes its rows. - Collect URLs: Extracts and stores all URLs listed under the
Profile URLcolumn. - Handle errors: Ensures the script can gracefully handle issues like missing files or invalid data.
This function uses the BrowserQL API to fetch the raw HTML content of each agent profile page. It sends a GraphQL mutation to load the page and retrieve its HTML.
const fetchHtmlFromBrowserQL = async (url) => {
const query = `
mutation FetchAgentPage {
goto(url: "${url}", waitUntil: networkIdle) { // Navigate to the URL
status
time
}
htmlContent: html(visible: false) { // Extract the HTML content
html
}
}
`;
const body = JSON.stringify({
query,
variables: {},
operationName: "FetchAgentPage",
});
try {
const response = await fetch(browserQLUrl, {
method: "POST", // Use POST for GraphQL requests
headers: { "Content-Type": "application/json" },
body,
});
if (!response.ok) {
throw new Error(
`Request failed with status ${response.status} for URL ${url}`,
);
}
const json = await response.json();
if (json.errors) {
console.error(
`BrowserQL returned errors for ${url}:`,
JSON.stringify(json.errors, null, 2),
);
return null;
}
return json.data.htmlContent.html; // Return the HTML content
} catch (error) {
console.error(`Error fetching HTML from BrowserQL for ${url}:`, error);
return null;
}
};
- GraphQL Query: Defines the actions for BrowserQL, including navigating to the URL and extracting the HTML content.
- Error Handling: Logs issues such as failed requests or API errors to ensure debugging is easier.
- Returns HTML: If successful, the function returns the raw HTML of the agent profile page.
Once we have the HTML, this function parses it to extract the agent’s name and phone number. It searches for these details within JSON-LD metadata embedded in the HTML.
const parseAgentData = (html, url) => {
try {
if (!html) throw new Error("HTML content is empty or null");
// Match agent name and phone number using regular expressions
const nameMatch = html.match(/"name":"([^&]+)"/);
const phoneMatch = html.match(/"telephone":"([^&]+)"/);
const name = nameMatch ? nameMatch[1] : "N/A"; // Extract name or default to 'N/A'
const phone = phoneMatch ? phoneMatch[1] : "N/A"; // Extract phone or default to 'N/A'
if (!name || !phone) {
console.error(`No valid data found for ${url}`);
}
return { name, phone }; // Return the parsed data
} catch (error) {
console.error(`Error parsing HTML for ${url}:`, error);
return { name: "Error parsing", phone: "Error parsing" }; // Return error details
}
};
- Extract Metadata: Searches the HTML for JSON-LD metadata that contains the agent’s name and phone number.
- Handle Missing Data: Logs a message if the required details are not found and returns default values.
- Return Parsed Data: Provides the extracted details in a structured format for further use.
After parsing, we save the extracted agent data into a CSV file. This function uses csv-writer to ensure the output is well-structured and easy to use.
const writeResultsToCsv = async (data) => {
const csvWriter = createCsvWriter.createObjectCsvWriter({
path: outputCsv, // Output file path
header: [
{ id: "url", title: "Profile URL" },
{ id: "name", title: "Name" },
{ id: "phone", title: "Phone" },
],
});
await csvWriter.writeRecords(data); // Write data to the CSV
console.log(`Results written to ${outputCsv}`); // Confirm completion
};
- Structured Output: Organizes the parsed data into columns for URLs, names, and phone numbers.
- Writes to File: Saves the data to parsed_output.csv for easy access and analysis.
Conclusion
With the right tools, Scraping Zillow data becomes significantly easier. BrowserQL’s advanced features, like natural interaction simulation and minimal footprints, make it a powerful option for overcoming anti-bot systems. Whether you’re gathering property data or agent information, BrowserQL streamlines the process for both small-scale and large-scale projects. Ready to get started? Sign up for a free BrowserQL trial and test it on your next scraping project.
**Is it legal to scrape data from Zillow? **Scraping public data is generally allowed, but always review Zillow’s terms of service and consult legal guidance to stay compliant.
**How does BrowserQL differ from Puppeteer and Playwright? **BrowserQL minimizes detectable footprints and automates human-like interactions, making it more effective at bypassing anti-bot systems.
**Can I integrate BrowserQL with existing scraping projects? **Yes, BrowserQL scripts can be exported and used with various tech stacks, including Puppeteer and Playwright.
**What if BrowserQL doesn’t bypass Zillow’s bot detection? **Browserless provides ongoing support to address site-specific challenges and stays updated on the latest anti-bot techniques.
**How do I get started with BrowserQL? **Sign up for a free trial on the Browserless website and download the BrowserQL IDE to begin creating and testing your scripts.