
Deploying Puppeteer on AWS EC2 is a powerful solution for automating browsers at scale, but it can be tricky to set up and maintain. There’s various issues you’ll run into such as OS compatibility and missing dependencies.
In this guide, we'll walk through setting up Puppeteer on an EC2 instance, from choosing the right instance type to installing necessary dependencies and configuring your environment for optimal performance.
{{banner}}
Choosing the Right EC2 Instance
When deploying Puppeteer on AWS EC2, selecting the appropriate instance type is key for performance. A t3.medium or t3.large instance with 4–8 GB of RAM is typically sufficient. In terms of storage, around 10 GB is recommended to handle Chromium and temporary files.
Unfortunately, Amazon Linux OS cannot be used for this setup due to missing dependencies required for Chromium and Puppeteer. While older Amazon Linux versions support EPEL (Extra Packages for Enterprise Linux) as mentioned here, they still lack key packages. Additionally, using EPEL involves risks, as mentioned in their documentation.
A better alternative is using Ubuntu on EC2, for which all required packages are available. However, it doesn’t integrate as seamlessly with other AWS services as Amazon Linux does, leading to more manual effort in setup.
Setting up EC2 and Puppeteer
Launch the EC2 instance with Ubuntu ensuring sufficient storage configurations and connect to it. Install node.js and puppeteer using the commands below.
We are also installing chromium here even though Puppeteer downloads its own Chromium by default.
Installing the system's Chromium ensures all necessary system dependencies are present. It also provides a fallback option if Puppeteer's version fails and allows for easier troubleshooting of system-specific issues.
Installing dependencies
Handling dependencies for Puppeteer across different operating systems and versions is complex due to varying system libraries and package management systems.
Ubuntu and other distributions may have different package names, versions, or availability. Figuring out the correct dependencies often requires trial and error, checking error messages, and adapting installation commands to each specific environment. This makes it a challenging task for developers to ensure consistent setup across diverse systems.
The following dependency list is tested for Ubuntu and is the latest working list. This previous list from 2018 is popular, but fails with few dependencies which might have changed in the due course of time.
Without the correct set of dependencies, Puppeteer fails with errors such as:
cannot open shared object file: No such file or directoryAn error occurred: Error: Failed to launch the browser process
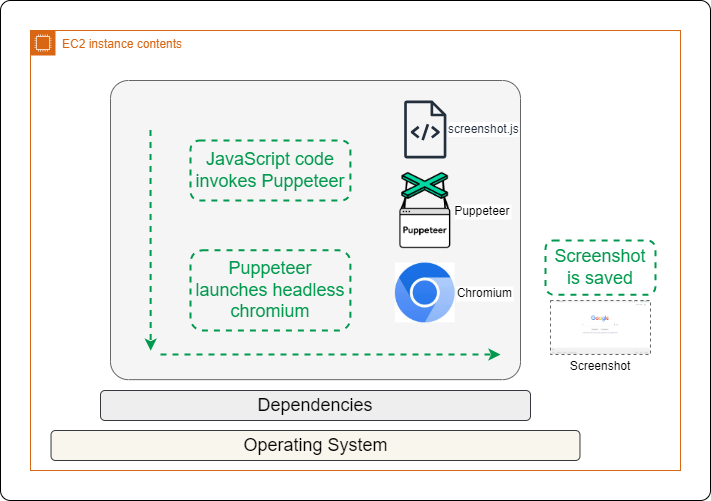
Writing the code
The following code saves the screenshots to the same directory code that is running.
Now you're ready to run a Puppeteer script to capture screenshots. Use following command to run the code -
Managing deployments
Managing the dependencies and maintaining them continuously is a time consuming task.
Dependency installation can be hindered by resource contention issues, such as apt cache locks. These occur when multiple package management processes attempt to access shared resources simultaneously, potentially leading to deadlock-like situations.
Troubleshooting typically involves terminating conflicting processes, cleaning up incomplete package installations, and releasing system-wide locks. Proper resolution requires careful handling to maintain system integrity while resolving conflicts.
That’s before you get into issues such as chasing memory leaks and clearing out zombie processes. Without those steps, Puppeteer can gradually require more and more resources.
Simplify your Puppeteer deployments with Browserless
To take the hassle out of scaling your scraping, screenshotting or other automations, try Browserless.
It takes a quick connection change to use our thousands of concurrent Chrome browsers. Try it today with a free account.
Want an easier option? Use our managed browsers
If you want to skip the hassle of deploying Chrome with it's many dependencies and memory leaks, then try out Browserless. Our pool of managed browsers are ready to connect to with a change in endpoint, with scaling available from tens to thousands of concurrencies.
You can either host just puppeteer-core without Chrome, or use our REST APIs. There’s residential proxies, stealth options, HTML exports and other common needed features.