Deploying Puppeteer on Azure VirtualMachines is a powerful solution for automating browsers at scale, but it can be tricky to set up and maintain. There’s various issues you’ll run into such m missing dependencies.
In this guide, we'll walk through setting up Puppeteer on an Azure VM, from choosing the right instance type to installing necessary dependencies and configuring your environment for optimal performance
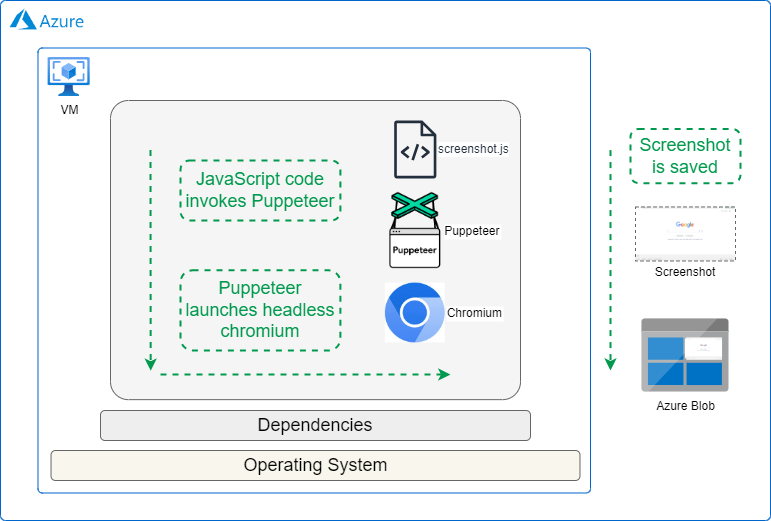
Choosing the Right Azure VM
When deploying Puppeteer on Azure, selecting the appropriate VM size is crucial for performance. A Standard_B2s or Standard_B2ms VM with 4-8 GB of RAM is typically sufficient for running Puppeteer effectively. For storage, allocating around 10 GB is recommended to accommodate Chromium and any temporary files generated during operations.
We will work with Ubuntu OS, which Azure VM suggests when provisioning the VM.
Setting up VM and Puppeteer
Launch the Azure VM with Ubuntu, ensuring sufficient storage configurations, and thenconnect to it. Install Node.js and Puppeteer using the commands below.
We would recommend also installing system Chromium: While Puppeteer downloads its own Chromium by default, installing it separately give you more control. This ensures all necessary system dependencies are present and provides a fallback option for troubleshooting.
Along with this, we also install Azure Storage Blob client library for JavaScript. This is required for VM to store screenshot in Azure blob.
# Update your system
sudo apt-get update
sudo apt-get upgrade
# Install curl if not already installed
sudo apt-get install -y curl
# Install Node.js (v22.x): Download and run the setup script
curl -fsSL https://deb.nodesource.com/setup_22.x -o nodesource_setup.sh
sudo -E bash nodesource_setup.sh
# Install Node.js
sudo apt-get install -y nodejs
# Verify Node.js installation
node -v
# Install Puppeteer
npm install puppeteer
# Install Chromium browser
sudo apt install -y chromium-browser
# Azure blob storage library
sudo npm install @azure/storage-blob
Installing dependencies
Dependency management sometimes becomes complex, as package names, versions, and availability may change over time and with different OS versions.
The following dependency list has been tested for Ubuntu on Azure VMs and represents the current working set. However, remember that as Ubuntu and Puppeteer evolve, this list may need updates.
#!/bin/bash
# Update package lists
sudo apt update
# Install dependencies
sudo apt install -y \
dconf-service \
libasound2t64 \
libatk1.0-0 \
libatk-bridge2.0-0 \
libc6 \
libcairo2 \
libcups2 \
libdbus-1-3 \
libexpat1 \
libfontconfig1 \
libgcc-s1 \
libgdk-pixbuf2.0-0 \
libglib2.0-0 \
libgtk-3-0 \
libnspr4 \
libpango-1.0-0 \
libpangocairo-1.0-0 \
libstdc++6 \
libx11-6 \
libx11-xcb1 \
libxcb1 \
libxcomposite1 \
libxcursor1 \
libxdamage1 \
libxext6 \
libxfixes3 \
libxi6 \
libxrandr2 \
libxrender1 \
libxss1 \
libxtst6 \
ca-certificates \
fonts-liberation \
libayatana-appindicator3-1 \
libnss3 \
lsb-release \
xdg-utils \
wget \
libgbm1
# Clean up
sudo apt autoremove -y
sudo apt clean
Without the correct set of dependencies, Puppeteer fails with errors such as:
cannot open shared object file: No such file or directoryAn error occurred: Error: Failed to launch the browser process
Configuring Azure Blob Storage
The code in the following section stores the screenshot in Azure blob, which required the connection string and container name. VM also needs a library to be installed to communicate with the blob which we’ve already installed in the previous section.
In Azure Portal, go to Storage accounts and select or create an account. Under Data storage, find Containers and create a new one, giving it a name (this is the container name). To get the connection string, access the Access keys section and copy the Connection string.
Use the container name you created and the copied connection string in your code where indicated.
Writing the code
The following code takes the website URL as input, captures a screenshot and saves it to Azure blob.
const puppeteer = require("puppeteer");
const { BlobServiceClient } = require("@azure/storage-blob");
const fs = require("fs");
// Get URL from command-line arguments
const url = process.argv[2];
if (!url) {
console.error(
"Please provide a URL as the first argument \n Ex - https://www.example.com",
);
process.exit(1);
}
// Azure Storage configuration
const connectionString = "your_connection_string"; // Replace with your connection string
const containerName = "your_container_name"; // Replace with your container name
async function captureScreenshot(
url,
outputPath,
viewportSize = { width: 1920, height: 1080 },
) {
let browser;
try {
// Launch a headless browser with improved performance
browser = await puppeteer.launch({
headless: "new",
args: ["--no-sandbox", "--disable-setuid-sandbox", "--disable-dev-shm-usage"],
defaultViewport: viewportSize,
});
const page = await browser.newPage();
// Set user agent to avoid detection as a bot
await page.setUserAgent(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
);
// Navigate to the website with a timeout
await page.goto(url, { waitUntil: "networkidle0", timeout: 60000 });
// Wait for the body to ensure the page has loaded
await page.waitForSelector("body");
// Capture and save the screenshot to the local directory (/tmp for EC2)
await page.screenshot({ path: outputPath, fullPage: true });
console.log(`Screenshot saved to ${outputPath}`);
// Read the screenshot file from local directory
const screenshotFile = fs.readFileSync(outputPath);
// Create a BlobServiceClient object using the connection string
const blobServiceClient =
BlobServiceClient.fromConnectionString(connectionString);
// Get the container client
const containerClient = blobServiceClient.getContainerClient(containerName);
// Define the blob name (filename in Azure Blob Storage)
const blobName = `screenshots/${url.replace(/https?:\/\//, "").replace(/\//g, "_")}.png`;
// Get a block blob client for the blob
const blockBlobClient = containerClient.getBlockBlobClient(blobName);
// Upload the screenshot to Azure Blob Storage
await blockBlobClient.upload(screenshotFile, screenshotFile.length, {
blobHTTPHeaders: { blobContentType: "image/png" },
});
console.log(`Screenshot uploaded to Azure Blob Storage at ${blobName}`);
} catch (error) {
console.error("An error occurred:", error);
} finally {
// Ensure the browser is closed even if an error occurs
if (browser) {
await browser.close();
}
}
}
// Usage: Pass URL and output file path via command line
(async () => {
const outputPath = "/tmp/screenshot.png"; // Temp location to save the screenshot before uploading
await captureScreenshot(url, outputPath);
})();
Now you're ready to run a Puppeteer script to capture screenshots. Use the following command to run the code (note the input format with https) -
node screenshot.js https://www.example.com
Managing deployments
Managing the dependencies and maintaining them continuously is a time consuming task.
Dependency installation can be hindered by resource contention issues, such as apt cache locks. These occur when multiple package management processes attempt to access shared resources simultaneously, potentially leading to deadlock-like situations.
Troubleshooting typically involves terminating conflicting processes, cleaning up incomplete package installations, and releasing system-wide locks. Proper resolution requires careful handling to maintain system integrity while resolving conflicts.
That’s before you get into issues such as chasing memory leaks and clearing out zombie processes. Without those steps, Puppeteer can gradually require more and more resources.
Simplify your Puppeteer deployments with Browserless
To take the hassle out of scaling your scraping, screenshotting or other automations, try Browserless.
It takes a quick connection change to use our thousands of concurrent Chrome browsers. Try it today with a free trial.