Glassdoor is a popular platform that offers a wealth of information, including job listings, company reviews, salary details, and interview experiences.
Accessing this data can help understand hiring trends, compare compensation, and analyze how companies are perceived in the job market. While the insights are valuable, scraping Glassdoor comes with challenges. To prevent automated access, the platform uses bot detection, CAPTCHAs, and dynamic content loading.
In this guide, you’ll learn how to scrape Glassdoor using Puppeteer and see how BrowserQL can make the process more efficient by automatically handling many obstacles.
Understanding Glassdoor’s Structure

Understanding Glassdoor’s structure is essential for scraping data effectively. The site organizes its content into different page types, each serving a distinct purpose. For example, job listings, company reviews, and salary data are separated into specific URLs with unique patterns. Recognizing these structures helps target the right information while reducing unnecessary requests.
Glassdoor’s Page Types
Job listing pages display information, including job titles, company names, locations, salary estimates, and detailed descriptions. These listings often contain filters for location, job type, and company, which affect how the data is structured on the page. The content is loaded dynamically, requiring you to handle JavaScript rendering when scraping. The URL pattern for accessing job listings is: https://www.glassdoor.com/Job/jobs.htm?sc.keyword=[keyword]
Company review pages provide insights into employee satisfaction, CEO approval ratings, and written comments from current and former employees. These pages are useful for analyzing workplace sentiment and trends over time. Much of the review content is hidden behind expandable sections or loaded as users scroll, so interacting with the page is often necessary to capture the full dataset. The URL structure for these pages is:
https://www.glassdoor.com/Reviews/[company]-reviews-SRCH_KE0,[id].htm
Salary pages present detailed compensation information, including estimated base pay, bonuses, and total pay ranges for specific roles and locations. This data is valuable for benchmarking salaries across industries and regions. Many salary figures are dynamically loaded and may require executing JavaScript to retrieve the complete information. The URL format for salary data follows this pattern:
https://www.glassdoor.com/Salaries/[location]-[job-title]-salary-SRCH_KO0,[id].htm
Understanding these page types and their URL patterns helps you focus on the right sections of the site when building scrapers. Different content structures may require adjusting your approach depending on what you’re extracting.
Use Cases for Scraping Glassdoor
Scraping Glassdoor opens up possibilities for understanding the job market, salary trends, and how people feel about their workplaces. Whether you’re looking to track hiring activity, compare compensation data, or analyze company sentiment, the information you gather can offer valuable insights.
Job Market Research
Looking at job postings on Glassdoor can help you see how hiring trends change over time. You can track which roles are in demand, how job opportunities vary across locations, and how industries respond to market shifts. Collecting this data regularly gives you a clearer picture of what companies are looking for and where job growth is happening.
Salary Benchmarking
Glassdoor’s salary information makes comparing pay across different jobs and regions easier. By gathering this data, you can spot trends in compensation, see how salaries differ for similar roles, and understand how location impacts earning potential. This can be helpful if you’re making hiring decisions or determining a fair salary for a particular job.
Company Sentiment Analysis
Employee reviews offer useful insights into people's feelings about working at a company. By analyzing this data, you can track changes in employee satisfaction, see how leadership is perceived, and identify patterns in workplace culture. This information can help you understand how companies are viewed by their teams and how those perceptions evolve.
Scraping Glassdoor Using Puppeteer

Scraping Glassdoor presents challenges like dynamic content loading, CAPTCHAs, and anti-bot protections. In this section, we’ll learn how to scrape software job listings in New York using Puppeteer to load the page and Cheerio to parse the HTML. We'll also save the extracted data to a CSV file for later use. Each step includes an explanation and corresponding code snippets.
Step 1: Install Dependencies
To get started, you’ll need to install the necessary libraries:
- Puppeteer: Automates the browser to navigate pages and load dynamic content.
- Cheerio: Parses the HTML using jQuery-like selectors.
- csv-writer: Saves the extracted data to a CSV file.
Install them with the following command:
npm install puppeteer cheerio csv-writer
Step 2: Fetch the HTML with Puppeteer
Puppeteer will load the Glassdoor job listings page and fetch the fully rendered HTML. This is important because job listings are loaded dynamically through JavaScript.
const puppeteer = require("puppeteer");
async function fetchHTML(url) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Set a user agent to reduce the chances of bot detection
await page.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
);
// Navigate to the URL and wait until the network is idle to ensure the page is fully loaded
await page.goto(url, { waitUntil: "networkidle2" });
// Extract the fully rendered HTML content
const html = await page.content();
await browser.close();
return html;
}
const jobUrl =
"https://www.glassdoor.com/Job/new-york-software-engineer-jobs-SRCH_IL.0,8_IC1132348_KO9,26.htm";
// Example usage
fetchHTML(jobUrl).then((html) => console.log(html));
This function opens a headless browser, sets a user agent to mimic a typical browser, navigates to the provided URL, waits until the page is fully loaded, and retrieves the HTML. This step is necessary to capture dynamically loaded content.
Step 3: Parse Job Listings with Cheerio
With the HTML fetched, you can use Cheerio to extract job details like titles, company names, locations, salaries, and descriptions.
const cheerio = require("cheerio");
function extractJobListings(html) {
const $ = cheerio.load(html); // Load HTML into Cheerio
const jobListings = [];
// Select each job card and extract details
$(".jobCard").each((_, element) => {
const jobTitle = $(element).find(".JobCard_jobTitle__GLyJ1").text().trim();
const companyName = $(element)
.find(".EmployerProfile_compactEmployerName__9MGcV")
.text()
.trim();
const location = $(element).find(".JobCard_location__Ds1fM").text().trim();
const salary = $(element).find(".JobCard_salaryEstimate__QpbTW").text().trim();
const description = $(element)
.find(".JobCard_jobDescriptionSnippet__l1tnl")
.text()
.trim();
if (jobTitle) {
jobListings.push({
jobTitle,
companyName,
location,
salary,
description,
});
}
});
return jobListings;
}
// Example usage
fetchHTML(jobUrl).then((html) => {
const jobs = extractJobListings(html);
console.log(jobs);
});
The extractJobListings function loads the HTML into Cheerio and uses CSS selectors to extract relevant job information. Each job card is processed to capture details like the title, company, location, salary, and job description.
Step 4: Save the Extracted Data to a CSV File
To make the data easier to analyze, you can save the extracted job listings into a CSV file.
const createCsvWriter = require("csv-writer").createObjectCsvWriter;
async function writeToCSV(jobListings) {
const csvWriter = createCsvWriter({
path: "job_listings.csv",
header: [
{ id: "jobTitle", title: "Job Title" },
{ id: "companyName", title: "Company Name" },
{ id: "location", title: "Location" },
{ id: "salary", title: "Salary" },
{ id: "description", title: "Description" },
],
});
try {
await csvWriter.writeRecords(jobListings); // Write job listings to CSV
console.log("Data successfully saved to job_listings.csv");
} catch (error) {
console.error("Error saving to CSV:", error);
}
}
// Example usage
fetchHTML(jobUrl).then((html) => {
const jobs = extractJobListings(html);
if (jobs.length) {
writeToCSV(jobs);
} else {
console.log("No job listings found.");
}
});
The writeToCSV function creates a CSV writer with defined headers and saves the job listings to a file named job_listings.csv. This allows you to store the extracted data in a structured format for further analysis.
Limitations of Scraping Glassdoor with Puppeteer

Scraping Glassdoor with Puppeteer can provide valuable data, but several challenges can slow down or block your efforts. These limitations range from anti-bot measures to technical hurdles when scaling up the scraping process.
Bot Detection & CAPTCHAs
Glassdoor uses advanced systems like CAPTCHAs and Cloudflare protection to detect and block automated browsing. After a few requests, you may encounter frequent CAPTCHAs that prevent further data extraction. Cloudflare can also recognize browsing patterns that don’t resemble typical human behavior, making it harder to scrape consistently without being flagged.
Rate Limiting & IP Bans
Glassdoor limits the number of requests you can send quickly to prevent abuse. Sending too many requests too quickly can result in temporary or permanent IP bans. Once flagged, regaining access to the site from the same IP address can be challenging, requiring alternative solutions to keep scraping.
Handling Dynamic Content
Many sections of Glassdoor, like salary details and company reviews, are loaded dynamically using JavaScript. Scraping these elements means waiting for the full page to render and executing scripts to access the complete content. If you do not handle this properly, you risk missing critical data or pulling incomplete information.
Scaling Issues
Running a single browser instance with Puppeteer works for small-scale scraping, but things get complicated when you need to scale. Managing multiple sessions at once increases resource consumption and technical complexity. To avoid detection, you’ll also need to implement proxy rotation, which adds another management layer to the process.
Using BrowserQL to Overcome Scraping Challenges
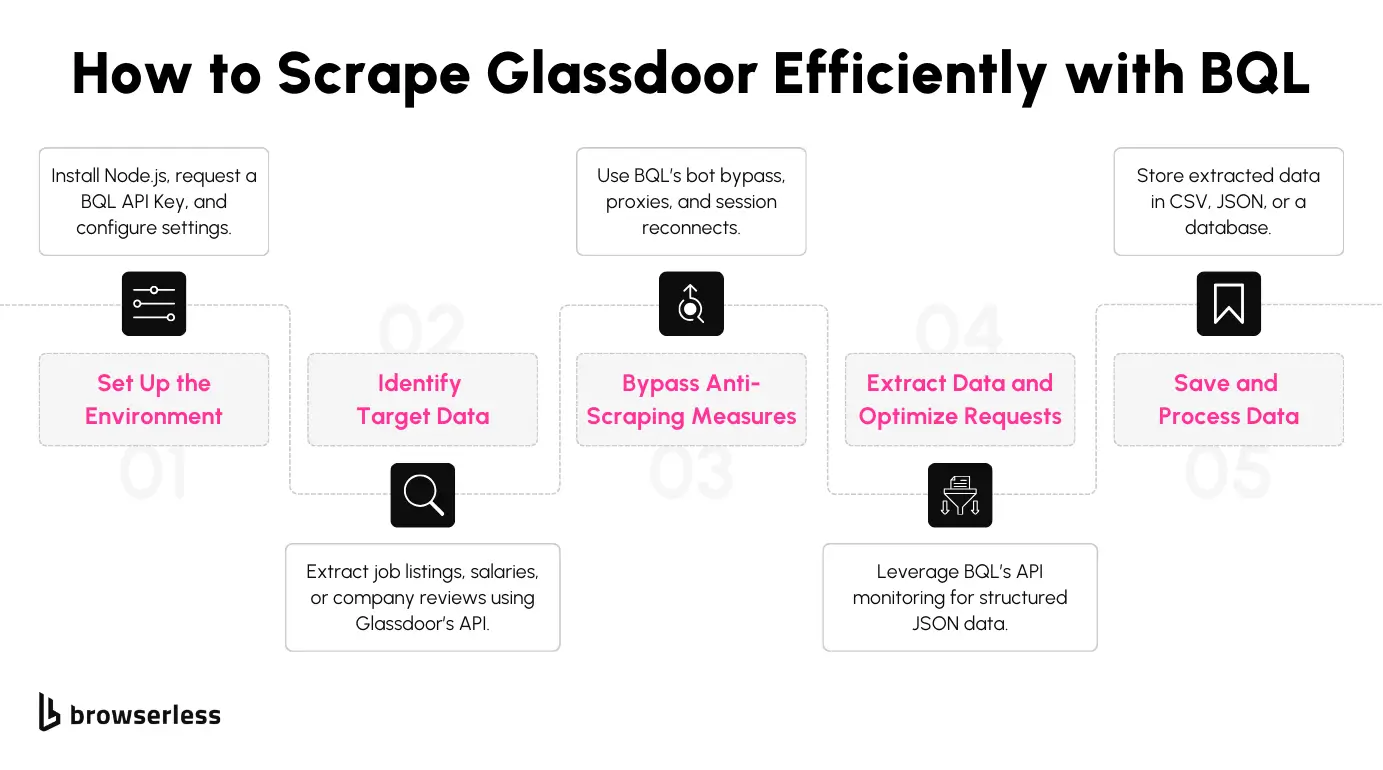
Scraping dynamic websites like Glassdoor presents challenges like JavaScript-loaded content, CAPTCHAs, and bot detection. BrowserQL (BQL) simplifies the process by allowing you to control headless browsers through structured queries. In this section, you’ll learn how to extract job listings from Glassdoor using BQL, making the process efficient and less prone to blocking.
Step 1: Install Dependencies
Start by installing the necessary libraries to handle HTTP requests, parse HTML, and save the extracted data. Run the following command:
npm install node-fetch@2 cheerio csv-writer
These packages enable you to send API requests (node-fetch), extract data from HTML (cheerio), and export results to a CSV file (csv-writer).
Step 2: Create the BQL Query
BQL provides a structured way to perform browser actions like navigating to pages and extracting content. The query below visits the Glassdoor job listings page, waits for the page to load fully, and retrieves the rendered HTML.
mutation scraping_example {
goto(
url: "https://www.glassdoor.com/Job/new-york-software-engineer-jobs-SRCH_IL.0,8_IC1132348_KO9,26.htm"
waitUntil: networkIdle
) {
status
}
html(selector: "body") {
html
}
}
The above query directs the browser to the target URL, waits for network activity to settle, and captures the HTML of the page body for extraction.
Step 3: Send the BQL Request
After preparing the BQL query, send it to the Browserless API using node-fetch. Replace the placeholders with your actual API credentials.
const fetch = require("node-fetch");
const endpoint = "YOUR_BROWSERLESS_PRODUCTION_URL";
const token = "YOUR_BROWSERLESS_API_KEY";
const bqlQuery = `
mutation scraping_example {
goto(url: "https://www.glassdoor.com/Job/new-york-software-engineer-jobs-SRCH_IL.0,8_IC1132348_KO9,26.htm", waitUntil: networkIdle) {
status
}
html(selector: "body") {
html
}
}
`;
async function fetchHTML() {
const response = await fetch(`${endpoint}?token=${token}`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
query: bqlQuery,
variables: {},
operationName: "scraping_example",
}),
});
const data = await response.json();
return data?.data?.html?.html;
}
This sends the BQL request to the Browserless API, retrieves the rendered HTML, and returns it for parsing.
Step 4: Parse the HTML Content
Once you have the rendered HTML, use cheerio to extract job details. This library allows you to select and extract elements using familiar CSS selectors.
const cheerio = require("cheerio");
function extractJobListings(html) {
const $ = cheerio.load(html);
const jobListings = [];
$(".JobCard_jobCardContent__JQ5Rq").each((_, element) => {
const jobTitle = $(element).find("a.JobCard_jobTitle__GLyJ1").text().trim();
const companyName = $(element)
.find("span.EmployerProfile_compactEmployerName__9MGcV")
.text()
.trim();
const location = $(element).find("div.JobCard_location__Ds1fM").text().trim();
const salary = $(element)
.find("div.JobCard_salaryEstimate__QpbTW")
.text()
.trim();
const description = $(element)
.find("div.JobCard_jobDescriptionSnippet__l1tnl")
.text()
.trim();
if (jobTitle || companyName || location) {
jobListings.push({ jobTitle, companyName, location, salary, description });
}
});
return jobListings;
}
This function targets job cards on the page and extracts details like the job title, company name, location, salary estimate, and description snippet.
Step 5: Save the Extracted Data
After extracting the job listings, save them to a CSV file for further analysis or reporting. Use the csv-writer library to handle the export.
const createCsvWriter = require("csv-writer").createObjectCsvWriter;
async function writeToCSV(jobListings) {
const csvWriter = createCsvWriter({
path: "job_listings_bql.csv",
header: [
{ id: "jobTitle", title: "Job Title" },
{ id: "companyName", title: "Company Name" },
{ id: "location", title: "Location" },
{ id: "salary", title: "Salary" },
{ id: "description", title: "Description" },
],
});
await csvWriter.writeRecords(jobListings);
}
This function writes the extracted job listings to a CSV file named job_listings_bql.csv, making it easy to work with the data in spreadsheet software or data analysis tools.
Step 6: Execute the Workflow
Combine the functions to fetch the HTML, extract job listings, and save the results. Before running the code, replace the placeholders with your actual API key and production URL.
(async () => {
const htmlContent = await fetchHTML();
const jobListings = extractJobListings(htmlContent);
if (jobListings.length > 0) {
await writeToCSV(jobListings);
console.log("Job listings saved to CSV.");
} else {
console.log("No job listings found.");
}
})();
This final step ties everything together. It retrieves the job listings from Glassdoor, processes the data, and saves the extracted information to a CSV file.
Conclusion
Scraping Glassdoor provides valuable insights into job postings, salary trends, and company reviews. While tools like Puppeteer can get the job done, they often require manual anti-bot measures, CAPTCHAs, and dynamic content handling. BQL simplifies this process by automating those challenges, making data extraction faster, more scalable, and less prone to interruptions. Sign up for a Browserless account today if you’re ready to streamline your scraping projects and spend less time dealing with roadblocks. Get started with BQL and see how much easier it can be to access your needed data.
FAQ
What data can I scrape from Glassdoor?
Glassdoor provides a wide range of information, including job listings, salary details, company reviews, interview questions, and CEO ratings. This data can be useful for job market analysis, competitive research, and understanding workplace sentiment.
How does BQL handle CAPTCHAs?
BQL automatically solves CAPTCHAs in the background, so you won’t need to intervene manually. It also reduces the likelihood of triggering CAPTCHAs by mimicking human-like browsing patterns, making your scraping sessions smoother and more efficient.
Can I scrape salaries from Glassdoor?
Yes, you can. However, salary information on Glassdoor often loads dynamically through JavaScript. BQL handles this by executing JavaScript during the scraping process, allowing you to capture full salary details that are unavailable through basic HTTP requests.
Will Glassdoor block my scraper?
Using standard scraping methods often leads to IP bans and blocked requests. BQL addresses this by managing IP rotation, maintaining session persistence, and bypassing common bot detection systems, helping your scraper stay undetected and running without