
Introduction
Shopify powers millions of online stores, making it a vital platform for e-commerce insights. Scraping Shopify stores provides pricing, inventory, and product details data for market research and trend analysis. However, challenges like rate limits, bot detection, and dynamic content can make it tricky. This article explores efficient scraping methods, overcoming challenges, and using tools like BrowserQL for streamlined workflows.
Understanding Shopify Store Structure
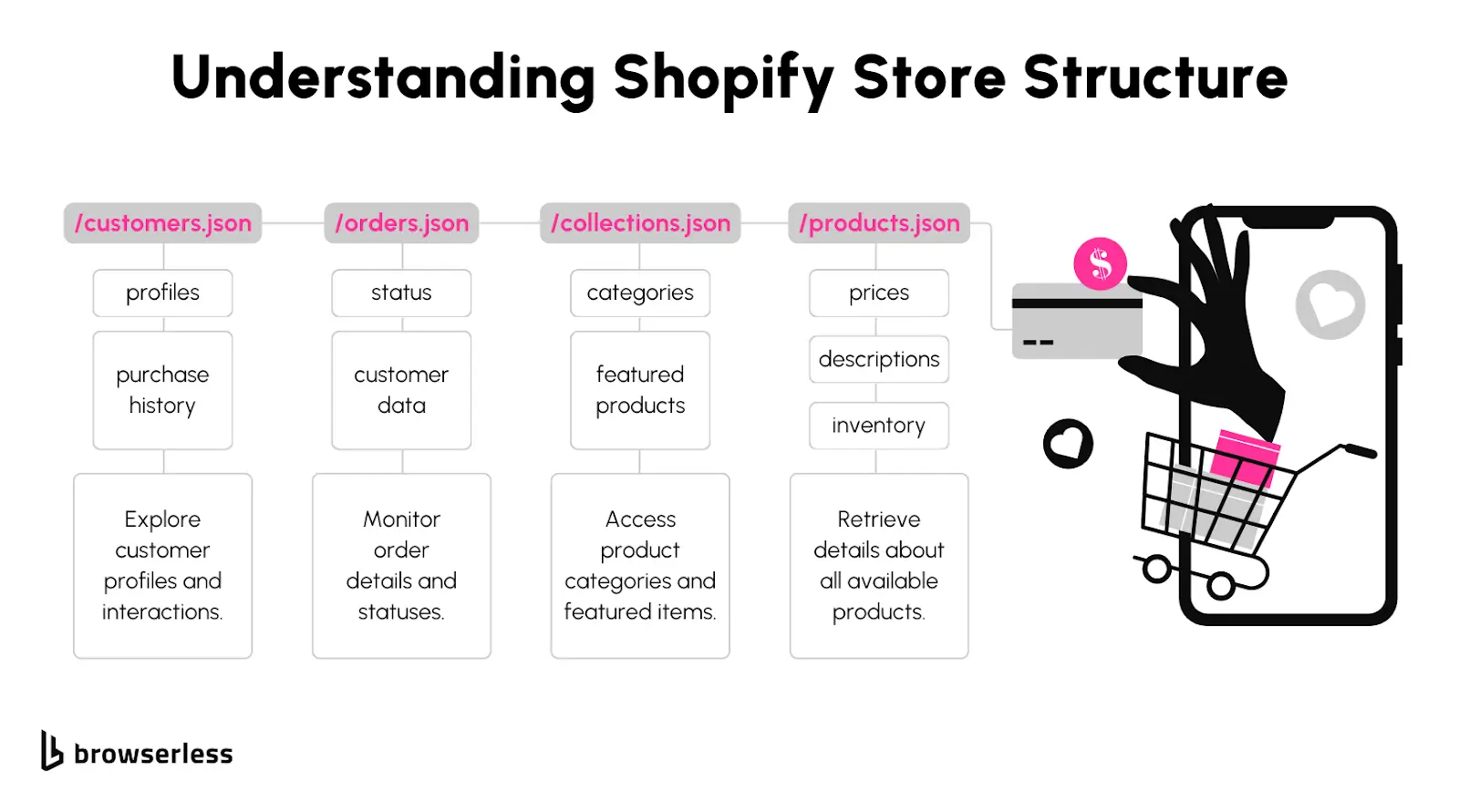
Shopify’s standardized setup makes it much easier to scrape than other platforms. With consistent patterns for URLs and easily accessible JSON endpoints, you can quickly locate and pull the data you need without too much guesswork. Let’s break it down.
Common Shopify URL Patterns
Shopify stores stick to predictable URL structures, which is great for scraping. Here are the main ones to know:
- Products: /products/[product-handle]
- Collections: /collections/[collection-handle]
- Categories: /collections/[category-handle]
- JSON Endpoints: /products.json, /collections.json
These patterns give you direct access to specific data types without digging through HTML. It’s like having a shortcut to the good stuff.
Data Types You Can Extract
When you scrape a Shopify store, you can grab a variety of useful information, much of which is available through the JSON endpoints.
Here’s what you’ll often find:
- Product Titles: The names of the items being sold.
- Prices: Regular and sale prices.
- Descriptions: Detailed product information and specs.
- Images: Links to all product images.
- Inventory Levels: Stock availability and quantities.
This structured data makes it simple to analyze or integrate into your projects.
Why JSON Endpoints Are So Helpful
The JSON endpoints are a big time-saver. Instead of parsing messy HTML, you get clean, ready-to-use data in a machine-readable format. That means you can spend less time cleaning up data and more time using it. Whether using BrowserQL, Cheerio, or another tool, JSON endpoints make your workflow faster, more reliable, and much easier to scale.
Use Cases for Scraping Shopify Stores

Market Research
Scraping Shopify stores gives you a direct window into pricing trends and product availability across competitors. You can use this data to identify pricing strategies, discounts, or new product launch patterns.
For instance, are your competitors lowering prices on specific products during certain seasons? Are there frequent inventory changes that could signal a trending product? Access to this information helps you fine-tune your pricing and stock strategies to stay ahead in the market.
Inventory Tracking
Keeping tabs on inventory levels and restocks from Shopify stores can be a game-changer. For example, you can spot when a competitor restocks a best-seller or a popular product is running low.
This insight helps you quickly identify high-demand items, adjust your inventory, and make more informed purchasing or stocking decisions. You can even use this data to predict trends by analyzing how stock levels shift over time.
Competitive Analysis
Want to know what’s working for your competitors? Scraping Shopify stores can help you uncover their top-performing products and even detect seasonal trends.
For example, collecting data on product categories, reviews, or featured items, you can understand what customers are gravitating toward. This insight can guide your decisions on which products to promote, add to your catalog, or even refine to meet customer demand better.
Product Research
Looking to refine your product offerings? Scraping Shopify stores gives you detailed access to product descriptions, customer reviews, and ratings. With this data, you can compare how similar products are positioned, identify features customers care about most, and spot areas where you can improve.
For example, you might discover a competitor’s product is consistently rated low for durability, allowing you to emphasize quality in your marketing. This kind of research ensures your products stand out and resonate with customers.
Tools for Scraping Shopify
Scraping Shopify stores efficiently requires the right tools. This section covers essential tools to streamline your process, handle challenges like dynamic content and anti-bot measures, and ensure accurate data extraction. Let’s dive in:
- BrowserQL: Handles dynamic content and scales effectively, making it a powerful option for large scraping projects.
- Cheerio: Useful for parsing HTML directly when Shopify’s JSON endpoints are unavailable.
- Proxy Services: Helps manage rate limits and avoids detection by spreading requests across multiple IPs.
Why BrowserQL Is an Ideal Choice
BrowserQL stands out because it simplifies scraping tasks that would otherwise be complicated by dynamic content or anti-bot mechanisms. Built-in support for handling dynamic pages and solving CAPTCHAs saves you from writing extra code to tackle those challenges.
BrowserQL's reusable sessions also allow you to reconnect to ongoing scraping tasks without starting from scratch, reducing data usage and speeding up workflows. For tasks that demand reliability and scalability, BrowserQL provides a streamlined way to extract Shopify store data efficiently.
Step-by-Step Tutorial
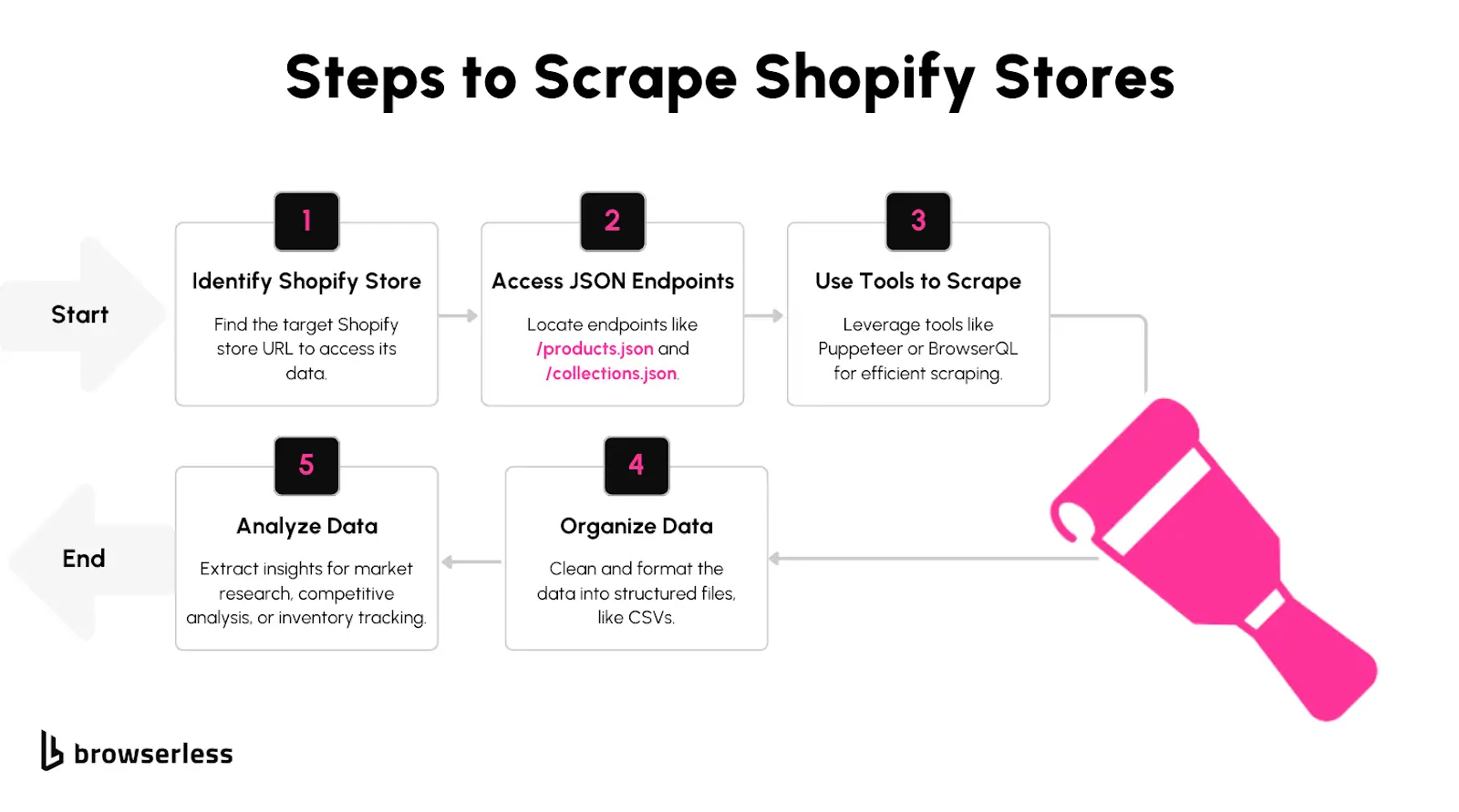
In this walkthrough, we’ll scrape Gymshark's Shopify store (gymshark.com) to extract product information like titles, prices, and inventory.
We’ll start with Shopify’s JSON endpoints, move to BrowserQL for dynamic pages, and optimize scraping using proxies and session reconnects.
Setting Up the Environment
Before starting, be sure to install the necessary tools below:
Required Tools
- Node.js – Download it from nodejs.org.
- BrowserQL API Key – Sign up for a free BrowserQL account and get your API key.
- Cheerio – Parses HTML when JSON endpoints aren’t available.
Once you have installed everything, let's get started.
Fetching Store Data
Shopify stores provide structured data via the /products.json endpoint. Let’s use it to grab Gymshark's product listings.
What’s happening?
- The script sends a GET request to Gymshark’s /products.json endpoint.
- It returns a list of products in structured JSON format, including names, prices, and inventory details.
- This method is fast and efficient for extracting public Shopify data.
Fetching Data with BrowserQL
If JSON endpoints are unavailable or blocked, we can use BrowserQL to extract product data directly from the webpage.
What’s happening?
- We use BrowserQL to visit Gymshark’s collection page.
- The query extracts product titles using the
h2.product-card__titleselector. - Unlike the JSON API, this method works even if Shopify hides the JSON endpoints.
Handling Dynamic Pages
Gymshark loads product details dynamically using JavaScript. If standard requests don’t return the required data, BrowserQL’s JavaScript execution can help.
What’s happening?
- We use BrowserQL to visit a Gymshark product page.
- The query extracts the product title and sale price, even if loaded dynamically.
- This ensures we capture accurate data, regardless of JavaScript-based rendering.
Optimizing for Scalability
To avoid getting blocked, we need proxies and session persistence.
Why use proxies?
- Prevents rate limits by distributing requests across multiple IPs.
- Reduces the risk of IP bans from Shopify’s anti-bot system.
Session Persistence with BrowserQL Reconnects
Instead of opening a new session for every request, BrowserQL allows you to reconnect to an existing session.
Why use reconnects?
- Saves time by avoiding unnecessary page reloads.
- Reduces proxy usage, lowering the risk of detection.
- Keeps cookies and sessions active, preventing CAPTCHA challenges..
Challenges and How to Overcome Them
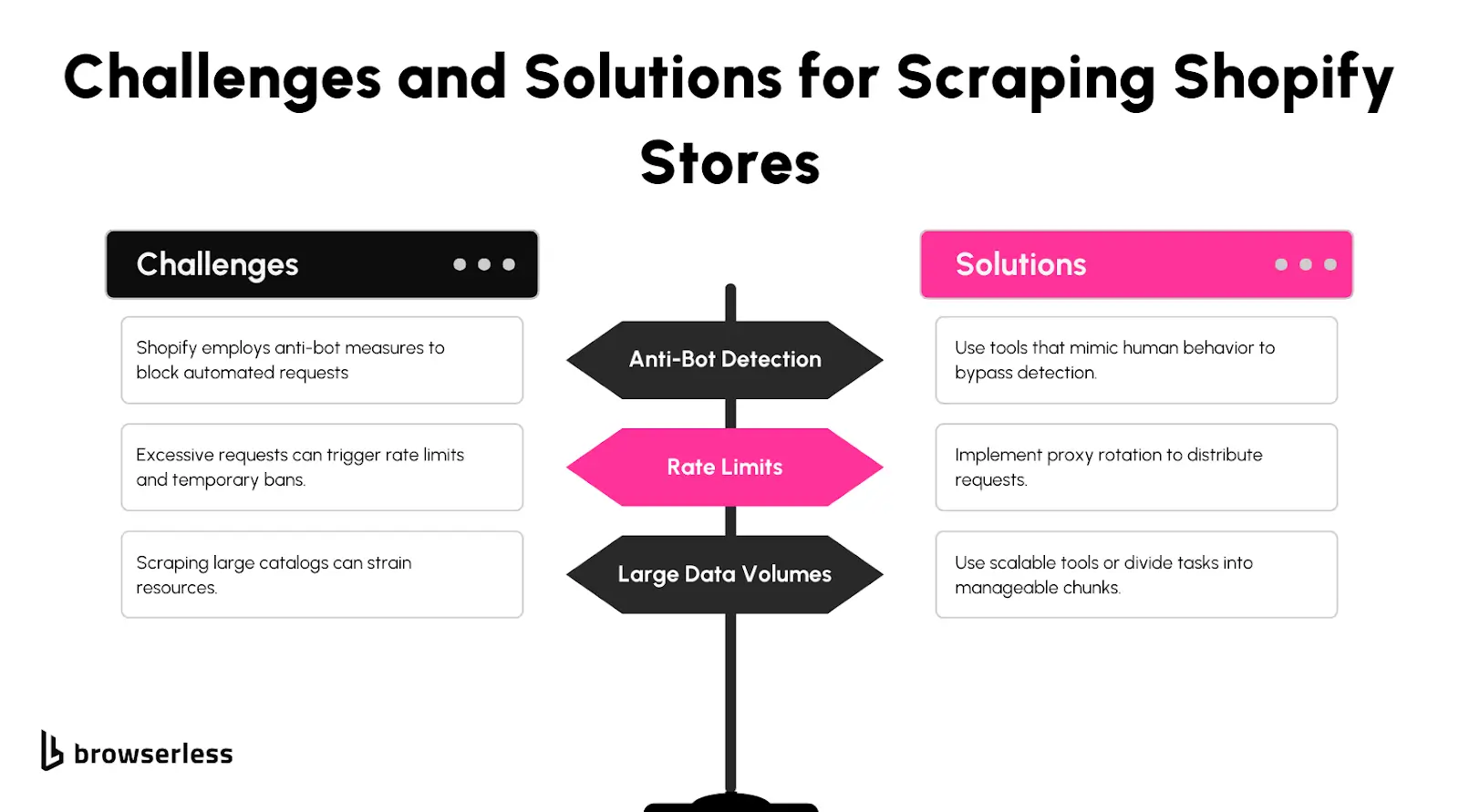
CAPTCHAs
CAPTCHAs can quickly become a major hurdle when scraping Shopify stores, but BrowserQL helps you deal with them efficiently. With built-in CAPTCHA-solving capabilities, BrowserQL can bypass these challenges without interrupting your workflow. This feature allows your scraping tasks to continue seamlessly, saving time and avoiding the frustration of manual CAPTCHA-solving.
Rate Limits
Shopify stores often impose rate limits to discourage excessive requests. To work around this, you can use proxy rotation and request throttling. Proxy rotation ensures that each request originates from a different IP address, reducing the chances of hitting rate limits. Pair this with request delays to mimic human-like browsing behavior, further decreasing the likelihood of triggering anti-scraping measures.
Dynamic Content
Many Shopify stores use JavaScript to render parts of their content, making it harder to scrape directly from HTML. With tools like BrowserQL, you can handle this efficiently by disabling JavaScript to speed up the scraping process or rendering the content when needed. This flexibility ensures you can extract the data you need, whether it’s visible immediately or dynamically generated.
Conclusion
Scraping Shopify stores provides valuable insights, from pricing trends to inventory tracking and product research. Shopify's structured architecture and JSON endpoints make data collection easier, while BrowserQL streamlines the process with tools for handling dynamic content, CAPTCHA mitigation, and optimized workflows. Whether for small projects or large-scale research, BrowserQL makes scraping faster and more efficient. Start your Shopify scraping project with BrowserQL today!
FAQ
What kind of data can I scrape from Shopify stores?
You can gather publicly visible data such as product names, prices, descriptions, images, inventory levels, and category information. Many Shopify stores provide JSON endpoints (like /products.json) that make it easy to extract structured data without diving into complex HTML parsing. This makes Shopify a popular target for data-driven research and analysis.
How does BrowserQL help with Shopify’s anti-scraping measures?
BrowserQL handles common scraping roadblocks like CAPTCHAs, rate limits, and session management. Its built-in CAPTCHA-solving feature saves you from manual intervention, while its session persistence and selective request handling reduce the chances of detection. These tools let you scrape efficiently and scale your workflows with less hassle.
Can I access hidden APIs from Shopify stores?
Yes, Shopify’s JSON endpoints are often publicly accessible and provide detailed data like product lists, collections, and stock levels. With BrowserQL, you can directly query these endpoints to fetch the needed data, skipping the challenges of parsing HTML. This makes scraping Shopify stores faster, simpler, and more scalable.