Introduction
Walmart is a go-to platform for millions of shoppers worldwide and a treasure trove of data for businesses and researchers. Whether you’re looking to analyze product details, monitor pricing, track availability, or dive into customer reviews, scraping Walmart can unlock valuable insights for competitive analysis and market research. But scraping Walmart isn’t a walk in the park. Traditional scraping tools often fall short with challenges like CAPTCHA defenses, IP rate limiting, and dynamic content.
Page Structure
Before scraping Walmart, it’s good to familiarize yourself with the site's setup. Walmart organizes its data into clear sections, like product search result pages and detailed product pages, making finding exactly what you’re looking for easier. Let’s take a closer look at what’s available.
Use Cases for Scraping Walmart
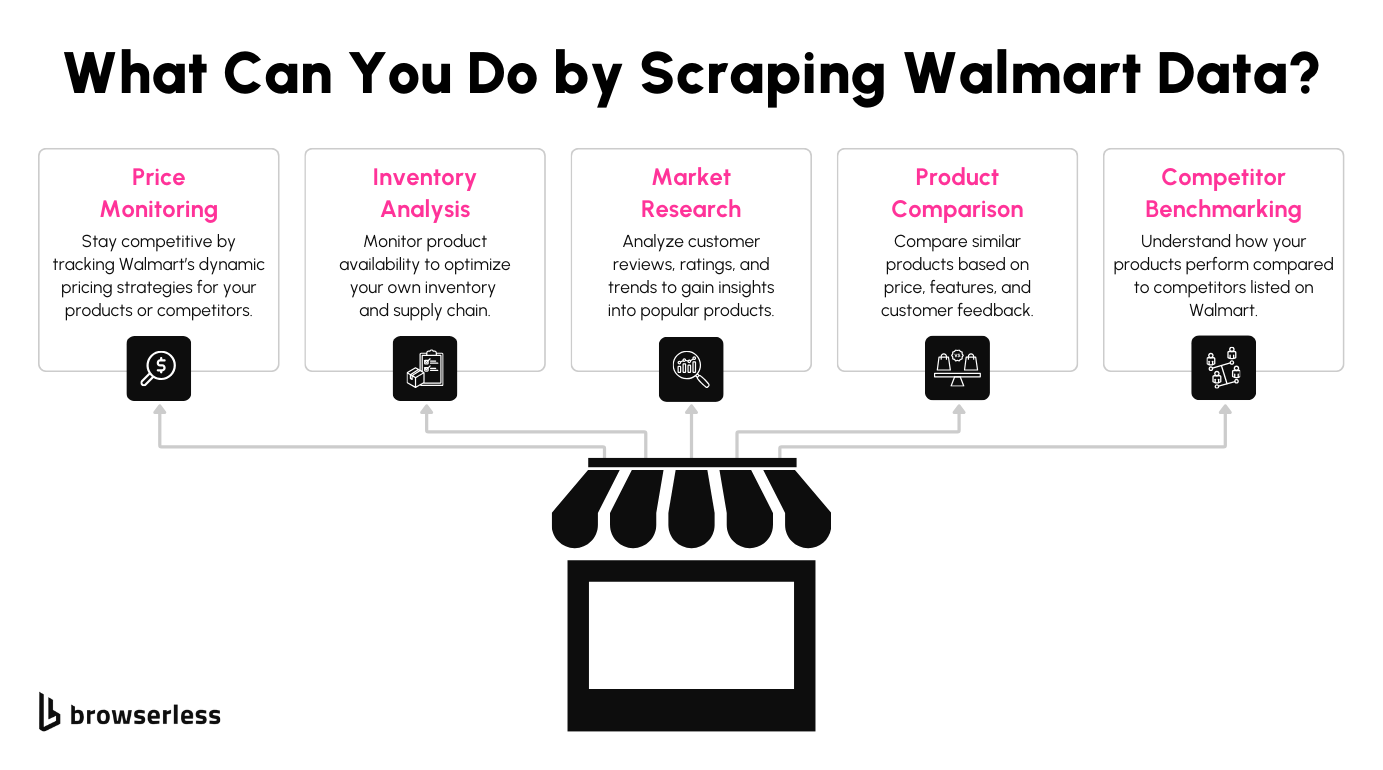
Scraping Walmart can help you unlock a ton of insights. Whether you’re tracking prices to stay competitive, analyzing reviews to understand customer sentiment, or gathering stock data to monitor availability, there’s so much value to be found. It’s a great way to build data-driven pricing, inventory, and market analysis strategies.
What Data Can You Scrape from Walmart?

Walmart’s site is packed with useful details. You can extract product names, prices, specifications, and even seller information. Customer reviews and stock availability add even more depth, making it a fantastic resource for anyone looking to gather detailed e-commerce data.
Product Search Results Pages
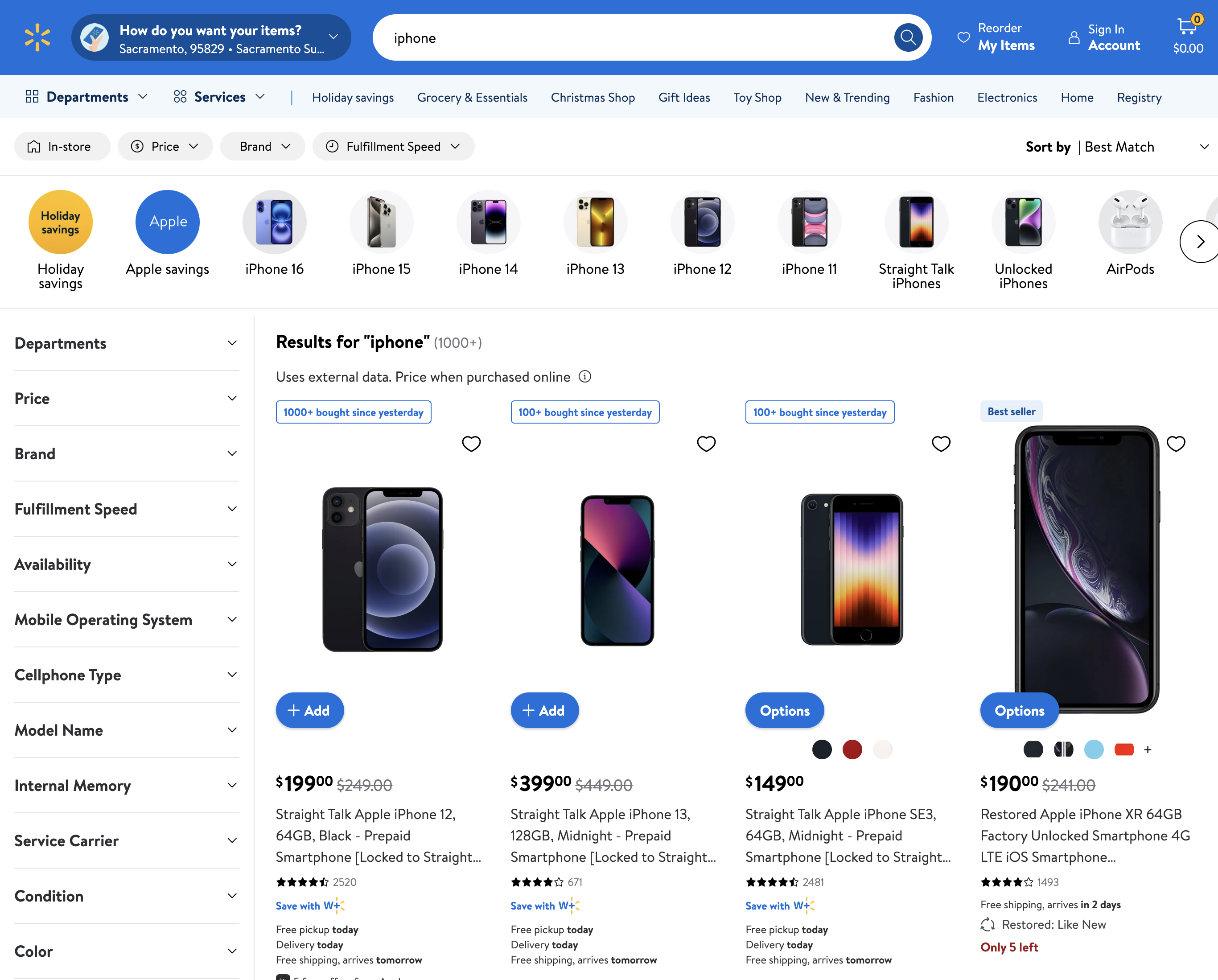
The search results pages give you a quick overview of products related to your search. These pages contain the basic details you’ll need to start your scrapping journey.
- Key Elements:Product titlesPricesStar ratingsLinks to product pages
- Product titles
- Prices
- Star ratings
- Links to product pages
These pages often include infinite scrolling or pagination, so you’ll want to account for that when pulling data.
Product Detail Pages

When you click on a product, the detail page opens up a world of information. Here, you’ll find the details that are perfect for deeper analysis.
- Data Points:Detailed descriptionsSpecifications (size, materials, etc.)Stock status (is it in stock? How many are left?)Customer reviews and ratingsSeller information
- Detailed descriptions
- Specifications (size, materials, etc.)
- Stock status (is it in stock? How many are left?)
- Customer reviews and ratings
- Seller information
These pages have everything you need to understand a product truly. Some sections may load dynamically, so be ready to handle that when designing your script.
How to Scrape Walmart with Puppeteer
Puppeteer is a powerful library for automating web scraping tasks. Here, we’ll walk through how to use Puppeteer to scrape Walmart product details. We’ll write two scripts: one for collecting product URLs from the search results page and another for scraping product details from those URLs.
Step 1: Setting Up Your Environment
Before we begin, make sure you have the following in place:
- Node.js: Install Node.js if you don’t already have it.
- Puppeteer: Install Puppeteer with the command
npm install puppeteer. - Basic JavaScript knowledge: You’ll need to tweak the script as needed.
We’ll be writing two short scripts: one to collect product URLs from a search page and another to extract product details like name, reviews, rating, and price.
Step 2: Collecting Products from the Search Page
Walmart’s search URLs are pretty straightforward: https://www.walmart.com/search?q={product_name}. For example, if you search for "iPhone," the URL becomes https://www.walmart.com/search?q=iphone. In this script, we’ll use a hardcoded URL to pull product links while adding some human-like interactions to avoid triggering CAPTCHAs.
import puppeteer from "puppeteer";
import fs from "fs/promises";
const sleep = (ms) => new Promise((resolve) => setTimeout(resolve, ms));
(async () => {
const SEARCH_URL = "https://www.walmart.com/search?q=iphone";
const OUTPUT_FILE = "walmart-product-urls.csv";
try {
// Start a browser session with headless mode off
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
console.log(`Heading over to ${SEARCH_URL}...`);
await page.goto(SEARCH_URL, { waitUntil: "networkidle2" });
// Add some scrolling to make things look more natural
console.log("Scrolling through the page like a real user...");
await page.evaluate(async () => {
for (let i = 0; i < 5; i++) {
window.scrollBy(0, 1000);
await new Promise((resolve) =>
setTimeout(resolve, 500 + Math.random() * 1000),
);
}
});
// Simulate mouse movement to mimic user behavior
console.log("Moving the mouse around to blend in...");
const clientHeight = await page.evaluate(() => document.body.clientHeight);
for (let i = 0; i < 5; i++) {
await page.mouse.move(Math.random() * 500, Math.random() * clientHeight, {
steps: 10,
});
await sleep(500 + Math.random() * 1000);
}
// Grab product links from the page
console.log("Extracting product URLs...");
const productUrls = await page.evaluate(() => {
const links = [];
document.querySelectorAll('a[href*="/ip/"]').forEach((el) => {
const href = el.getAttribute("href");
if (href) links.push(`https://www.walmart.com${href}`);
});
return links;
});
console.log(`Found ${productUrls.length} product URLs!`);
console.log("Saving them to a CSV file...");
// Save the URLs into a CSV
const csvData = productUrls.map((url) => `"${url}"`).join("\n");
await fs.writeFile(OUTPUT_FILE, csvData);
console.log(`URLs saved to ${OUTPUT_FILE}.`);
await browser.close();
} catch (error) {
console.error("Uh-oh, something went wrong:", error);
}
})();
What’s Happening?
SEARCH_URL: This is the Walmart search page URL for our query—in this case, "iPhone."- Starting the Browser: We launch Puppeteer with
headless: falseto make our bot look more like a regular user. - Scrolling: Simulates natural scrolling behavior with pauses and randomness to avoid detection.
- Mouse Movement: Random mouse movements add another layer of human-like interaction.
- Extracting Links: The script identifies all ``tags with
/ip/in theirhref, which are unique to Walmart product pages, and saves the full URLs. - Saving the Data: All the extracted URLs are written to a CSV file for further processing.
Step 3: Collecting Product Details from URLs
With all product URLs collected, we can now extract specific details like the product name, price, and ratings. This script will read URLs from the CSV file, visit each product page, and scrape the desired details.
import puppeteer from "puppeteer";
import fs from "fs";
// Constants
const INPUT_FILE = "walmart-product-urls.csv";
const OUTPUT_FILE = "walmart-product-details.csv";
const MAX_RETRIES = 3;
// Utility function to sanitize URLs
const sanitizeUrl = (url) => {
try {
return encodeURI(url.trim());
} catch (error) {
console.error(`Invalid URL skipped: ${url}`);
return null;
}
};
// Function to scrape product details
const scrapeProductDetails = async (page, url, retries = 0) => {
try {
console.log(`Visiting "${url}"...`);
await page.goto(url, { waitUntil: "networkidle2", timeout: 60000 });
// Extract product details
return await page.evaluate(() => {
const getText = (selector) =>
document.querySelector(selector)?.innerText.trim() || "N/A";
const name = getText("#main-title");
const price = getText('[itemprop="price"]');
const ratingElement = document.querySelector(
'span[itemprop="ratingValue"]',
)?.innerText;
const ratingCountElement = document.querySelector(
'[itemprop="ratingCount"]',
)?.innerText;
const rating =
ratingElement && ratingCountElement
? `${ratingElement} stars from ${ratingCountElement} reviews`
: "N/A";
return { name, price, rating };
});
} catch (error) {
console.error(`Failed to scrape "${url}": ${error.message}`);
if (retries < MAX_RETRIES) {
console.log(`Retrying (${retries + 1}/${MAX_RETRIES})...`);
return await scrapeProductDetails(page, url, retries + 1);
}
return { url, error: error.message, name: "N/A", price: "N/A", rating: "N/A" };
}
};
// Main function
(async () => {
try {
// Load URLs
const urls = fs
.readFileSync(INPUT_FILE, "utf-8")
.split("\n")
.map(sanitizeUrl)
.filter(Boolean);
console.log(`Found ${urls.length} product URLs. Starting to scrape...`);
// Launch browser
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
const scrapedData = [];
for (const url of urls) {
const data = await scrapeProductDetails(page, url);
scrapedData.push({ ...data, url });
}
await browser.close();
// Save scraped data
const csvData = ["Name,Price,Rating,URL"];
scrapedData.forEach((data) => {
csvData.push(`"${data.name}","${data.price}","${data.rating}","${data.url}"`);
});
fs.writeFileSync(OUTPUT_FILE, csvData.join("\n"), "utf-8");
console.log(`Scraping complete! Data saved to ${OUTPUT_FILE}`);
} catch (error) {
console.error(`Error: ${error.message}`);
}
})();
What’s Happening?
- Read URLs:The script reads product URLs from the
walmart-product-urls.csvfile and sanitizes them usingencodeURI()to handle any formatting issues. - The script reads product URLs from the
walmart-product-urls.csvfile and sanitizes them usingencodeURI()to handle any formatting issues. - Visit Pages:Puppeteer navigates to each URL and waits for the page to fully load (
networkidle2). - Puppeteer navigates to each URL and waits for the page to fully load (
networkidle2). - Extract Details:The script uses
querySelectorto target specific product details:Name: Extracted from the#main-titleelement.Price: Scraped from the element with[itemprop="price"].Rating: Combined value of star ratings ([itemprop="ratingValue"]) and total reviews ([itemprop="ratingCount"]). - The script uses
querySelectorto target specific product details:Name: Extracted from the#main-titleelement.Price: Scraped from the element with[itemprop="price"].Rating: Combined value of star ratings ([itemprop="ratingValue"]) and total reviews ([itemprop="ratingCount"]). - Name: Extracted from the
#main-titleelement. - Price: Scraped from the element with
[itemprop="price"]. - Rating: Combined value of star ratings (
[itemprop="ratingValue"]) and total reviews ([itemprop="ratingCount"]). - Retry on Errors:If a page fails to load or an error occurs during scraping, the script retries up to three times.
- If a page fails to load or an error occurs during scraping, the script retries up to three times.
- Save to CSV:Scraped data is saved to
walmart-product-details.csvin a structured format with columns for the product name, price, rating, and URL. - Scraped data is saved to
walmart-product-details.csvin a structured format with columns for the product name, price, rating, and URL.
These scripts give you a straightforward way to scrape Walmart using Puppeteer. They’re also flexible, and you can expand them to handle additional data points or more complex workflows.
However, while running the script in Step 3, you might come into issues when scraping a large number of product URLs with a capita challenge like this:

So how do you handle this? That's what we will cover in the next section.
Scaling Limitations

You might have encountered CAPTCHAs when trying to scrape Walmart’s product listings. These challenges are part of Walmart’s measures to prevent automated tools from accessing their site. Let’s look at the hurdles they’ve put in place and how they impact scraping efforts.
CAPTCHA Challenges
CAPTCHAs are designed to distinguish between humans and bots. When requests to Walmart’s servers become too frequent or suspicious, CAPTCHA challenges are triggered. These challenges often block access until the user completes a task, such as identifying specific objects in images. For automated scripts, this presents a significant roadblock.
IP Blocking
If traffic from an IP address seems abnormal, Walmart can block that address entirely. This happens when patterns such as repeated requests in a short time or requests to a large number of pages occur. Such behavior deviates from what a typical user would do, leading to the server denying access from that source.
Detecting Non-Human Behaviors
Behaviors like rapid scrolling, clicking links at precise intervals, or accessing pages faster than a human could indicate the presence of a bot. Walmart’s systems monitor for these patterns and flag any activity that doesn’t align with how real users interact with their site.
Dynamically Loaded Content
Many elements on Walmart’s pages, like reviews and product availability, are loaded dynamically using JavaScript. These elements may not be immediately available in the HTML source. Traditional scrapers struggle with this because they can’t process the JavaScript required to render the full page content.
Overcoming These Limitations with BrowserQL
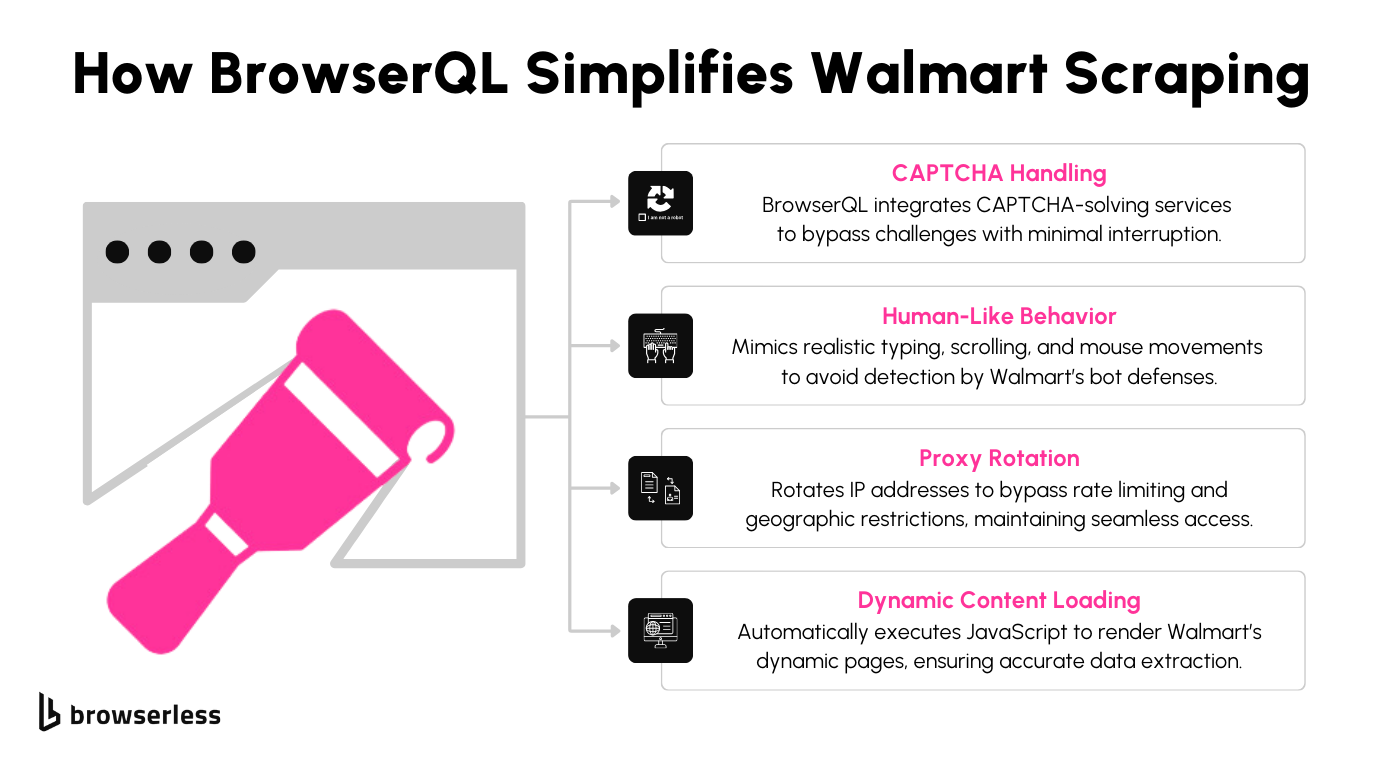
BrowserQL offers a way to handle these challenges effectively. It simulates human-like interactions, such as realistic scrolling and clicking patterns, making it harder for Walmart’s systems to distinguish it from a real user.
BrowserQL also integrates tools to solve CAPTCHAs, allowing the script to continue when a challenge appears. Additionally, it supports proxy management, enabling requests from IP addresses and reducing the likelihood of being blocked.
Setting Up BrowserQL for Walmart Scraping
Step 1: Create a Browserless Account and Retrieve Your API Key
The first step to using BrowserQL for Walmart scraping is signing up for a Browserless account. Once registered, log in and head over to your account dashboard. There, you’ll find a section dedicated to API keys.
Locate your unique API key and copy it. This will be used to authenticate all your requests to the BrowserQL API. The dashboard also provides insights into your usage and subscription details, so you can easily keep track of your activity and API calls.

Caption: Navigate to the BrowserQL Editors section from your dashboard.
Step 2: Set Up Your Development Environment
Before writing your scripts, make sure your development environment is ready. Install Node.js, which you’ll use to run your scripts. Once Node.js is installed, open your terminal and use the following commands to install the required packages:
npm install node-fetch cheerio
These libraries allow your script to send requests to the BrowserQL API and process the HTML responses you’ll receive from Walmart product pages.
Step 3: Download and Install the BrowserQL Editor
BrowserQL offers an editor that simplifies crafting and testing queries. You can download this editor directly from your Browserless dashboard:
- Navigate to the BrowserQL Editors section in the left-hand sidebar.
- Select the version compatible with your operating system, such as macOS, Windows, or Linux.
- Click the download link and follow the installation steps.
Caption: Download the BrowserQL Editor for your operating system.
Once installed, the BrowserQL Editor provides a simple and interactive interface for testing and optimizing your scraping queries before integrating them into your Walmart scraping scripts.
Step 4: Run a Basic Test Query
Before jumping into Walmart scraping, it’s essential to test your setup to ensure everything works as expected. Here’s a sample query to test BrowserQL by loading Walmart’s homepage:
mutation TestWalmartQuery {
goto(url: "https://www.walmart.com", waitUntil: networkIdle) {
status
time
}
}
Copy and paste this query into the BrowserQL Editor and execute it. The response should return a status code and the time it took to load the page. This test confirms that your API key and setup are functioning correctly. Once your test query works, you’re ready to create more advanced scripts to scrape product data, reviews, and other details from Walmart.
Writing Our BrowserQL Script
Part 1: Collecting Product URLs from the Search Page
To gather product URLs from Walmart, we’ll begin by loading the search results page, extracting the HTML with BrowserQL, and parsing it to find product links. These links will then be stored in a CSV file for further processing.
Start by importing the necessary libraries and defining constants for the script. These include the BrowserQL API endpoint, an API token, and paths for the input and output files.
import fetch from "node-fetch"; // For API requests
import * as cheerio from "cheerio"; // For parsing HTML
import { createObjectCsvWriter } from "csv-writer"; // For writing data to CSV
// Constants
const BROWSERQL_URL = "https://production-sfo.browserless.io/chromium/bql";
const TOKEN = "your_api_token"; // Replace with your BrowserQL API token
const OUTPUT_CSV = "product_urls.csv"; // File to store extracted product URLs
const SEARCH_URL = "https://www.walmart.com/search?q=iphone"; // Example search URL
- BrowserQL URL: Specifies the API endpoint for executing scraping requests.
- API Token: Authorizes requests made to the BrowserQL service.
- Output File: Identifies where the extracted product URLs will be saved.
- Search URL: Represents the Walmart search page to scrape for product listings.
Next, we’ll create a BrowserQL mutation to open the search results page, wait for the content to load, and fetch the HTML.
const query = `
mutation ScrapeSearchPage {
goto(url: "${SEARCH_URL}", waitUntil: networkIdle) {
status
time
}
waitForTimeout(time: 3000) {
time
}
htmlContent: html(visible: false) {
html
}
}
`;
(async () => {
console.log(`Fetching search results from: ${SEARCH_URL}`);
const response = await fetch(`${BROWSERQL_URL}?token=${TOKEN}`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ query }),
});
const data = await response.json();
const html = data?.data?.htmlContent?.html;
if (!html) {
console.error("Failed to fetch HTML from the search page.");
return;
}
// Parse HTML for product URLs
const $ = cheerio.load(html);
const urls = [];
$("a[href*='/ip/']").each((_, element) => {
const productPath = $(element).attr("href");
if (productPath) urls.push(`https://www.walmart.com${productPath}`);
});
console.log(`Found ${urls.length} product URLs.`);
// Write URLs to CSV
const csvWriter = createObjectCsvWriter({
path: OUTPUT_CSV,
header: [{ id: "Product URL", title: "Product URL" }],
});
await csvWriter.writeRecords(urls.map((url) => ({ "Product URL": url })));
console.log(`Product URLs saved to ${OUTPUT_CSV}`);
})();
- GraphQL Query: Sends instructions to BrowserQL for scraping the search page.
- HTML Parsing: Extracts product links by identifying elements containing
/ip/in theirhref. - URL Formatting: Converts relative paths into absolute URLs by appending the base domain.
- CSV Output: Stores the collected product links in a structured CSV file.
Part 2: Extracting Product Details
With the product URLs saved, the next step is to visit each product page and scrape details such as the product name, price, rating, and the number of reviews.
Step 1: Define Constants and Read Input CSV
The script defines constants for the BrowserQL API and paths for the input and output CSV files. It then reads product URLs from the input CSV.
// Constants
const BROWSERQL_URL = "https://production-sfo.browserless.io/chromium/bql";
const TOKEN = "your_api_token_here"; // Replace with your actual BrowserQL API token
const INPUT_CSV = "walmart-bql-product-urls.csv"; // File containing product URLs
const OUTPUT_CSV = "walmart-product-details.csv"; // Output file for product details
// Function to read product URLs from a CSV file
const readProductUrls = async (filePath) => {
const urls = [];
return new Promise((resolve, reject) => {
fs.createReadStream(filePath)
.pipe(csvParser())
.on("data", (row) => {
console.log("Row read from CSV:", row); // Debugging log
if (row["Product URL"]?.trim()) {
urls.push(row["Product URL"].trim());
}
})
.on("end", () => {
console.log("URLs loaded:", urls); // Debugging log
resolve(urls);
})
.on("error", (error) => reject(error));
});
};
- Reading URLs: Extracts product links from the input CSV file.
- Validation: Filters out empty or invalid entries.
- Output Collection: Gathers the URLs in an array for processing.
Step 2: Fetch HTML Using BrowserQL
For each product URL, the script retrieves the HTML content using a GraphQL mutation via BrowserQL.
// BrowserQL Mutation to Fetch HTML Content
const fetchHtmlFromBrowserQL = async (url) => {
const query = `
mutation FetchProductDetails {
goto(url: "${url}", waitUntil: networkIdle) {
status
time
}
waitForTimeout(time: 3000) {
time
}
htmlContent: html(visible: true) {
html
}
}
`;
const body = JSON.stringify({
query,
variables: {},
operationName: "FetchProductDetails",
});
console.log("Sending BrowserQL request for URL:", url); // Debugging log
console.log("Request body:", body); // Debugging log
try {
const response = await fetch(`${BROWSERQL_URL}?token=${TOKEN}`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body,
});
const data = await response.json();
if (data?.data?.htmlContent?.html) {
console.log(`HTML content successfully retrieved for URL: ${url}`); // Debugging log
} else {
console.error(`Failed to retrieve HTML content for URL: ${url}`); // Debugging log
}
return data?.data?.htmlContent?.html || null;
} catch (error) {
console.error(`Error fetching HTML for URL ${url}:`, error);
return null;
}
};
- GraphQL Mutation: Sends a request to BrowserQL to load the product page and retrieve its HTML content.
- Error Handling: Logs network or data retrieval issues for troubleshooting.
- HTML Retrieval: Returns the HTML content for further processing.
Step 3: Parse Product Details and Save to CSV
Using Cheerio, the script extracts specific product details from the HTML content and writes them to an output CSV file.
// Function to Parse Product Details
const parseProductDetails = (html, url) => {
const $ = cheerio.load(html);
const name = $("h1#main-title").text().trim() || "N/A";
const price = $('span[itemprop="price"]').text().trim() || "N/A";
const rating =
$("div.w_iUH7")
.text()
.match(/[\d.]+/)?.[0] || "N/A";
const reviews =
$('a[itemprop="ratingCount"]').text().trim().replace(/\D+/g, "") || "0";
return { url, name, price, rating, reviews };
};
// Function to Save Product Details to CSV
const saveProductDetailsToCsv = async (data) => {
const csvWriter = createObjectCsvWriter({
path: OUTPUT_CSV,
header: [
{ id: "url", title: "Product URL" },
{ id: "name", title: "Product Name" },
{ id: "price", title: "Price" },
{ id: "rating", title: "Rating" },
{ id: "reviews", title: "Number of Reviews" },
],
});
await csvWriter.writeRecords(data);
console.log(`Product details saved to ${OUTPUT_CSV}`);
};
// Main Process
(async () => {
try {
console.log(`Reading product URLs from ${INPUT_CSV}`);
const productUrls = await readProductUrls(INPUT_CSV);
if (!productUrls.length) {
console.error(
"No product URLs found in the CSV file. Please check the file format.",
);
return;
}
console.log(`Loaded ${productUrls.length} product URLs.`);
const productDetails = [];
for (const url of productUrls) {
console.log(`Processing ${url}`);
const html = await fetchHtmlFromBrowserQL(url);
if (html) {
const details = parseProductDetails(html, url);
productDetails.push(details);
} else {
console.error(`Failed to fetch HTML for URL: ${url}`);
}
}
if (productDetails.length) {
await saveProductDetailsToCsv(productDetails);
console.log(`Scraping complete. Details saved to ${OUTPUT_CSV}`);
} else {
console.error(
"No product details were scraped. Please verify the URLs and selectors.",
);
}
} catch (error) {
console.error("Error in scraping process:", error);
}
})();
- Parsing Details: Extracts the product name, price, rating, and review count from the HTML.
- Data Structuring: Formats the parsed data into an array of objects.
- CSV Output: Saves the collected product details to a CSV file for further analysis.
Conclusion
BrowserQL makes scraping Walmart smoother and more efficient. It removes the headaches of bypassing CAPTCHAs, navigating dynamic content, and avoiding anti-bot systems. Whether researching products, tracking prices, or analyzing reviews, BrowserQL lets you do it all seamlessly, without interruptions. By handling even the trickiest parts of scraping e-commerce sites like Walmart, BrowserQL opens up new possibilities for gathering valuable data. Ready to simplify your data collection and scale your insights? Sign up for BrowserQL and discover what it can do for Walmart and other platforms!
FAQ
Is scraping Walmart legal?
Scraping public product data is generally permissible, but it’s important to review Walmart’s terms of service to ensure compliance and avoid abusive scraping practices that could disrupt their platform.
What can I scrape from Walmart?
You can extract product details, pricing, stock availability, customer reviews, and seller information all valuable for market research and competitive analysis.
How does BrowserQL handle Walmart’s anti-bot defenses?
BrowserQL uses human-like interactions, supports proxies, and minimizes browser fingerprints to reduce detection. This combination allows for smooth scraping even with Walmart’s defenses in place.
Can I scrape all product reviews on Walmart?
Yes, BrowserQL supports handling pagination and dynamic loading, enabling you to collect all reviews for a product without missing any data.
Does Walmart block automated scrapers?
Walmart employs strong anti-bot measures, such as CAPTCHA challenges and IP rate limiting. BrowserQL is specifically engineered to overcome these obstacles.
Can I scrape Walmart without triggering CAPTCHAs?
BrowserQL’s human-like browsing behavior significantly reduces CAPTCHA occurrences. For those rare instances where CAPTCHAs appear, BrowserQL integrates with CAPTCHA-solving services to maintain uninterrupted scraping.