Modern websites use network requests to load dynamic content, making traditional scraping methods that rely on HTML parsing less effective. As applications increasingly use API calls and JavaScript-driven data loading, capturing network requests provides a more direct and reliable way to access structured data. This guide explores how network scraping works, its use cases, its limitations, and how tools like BQL simplify the process for more efficient data extraction.
How Network Requests Power Modern Websites
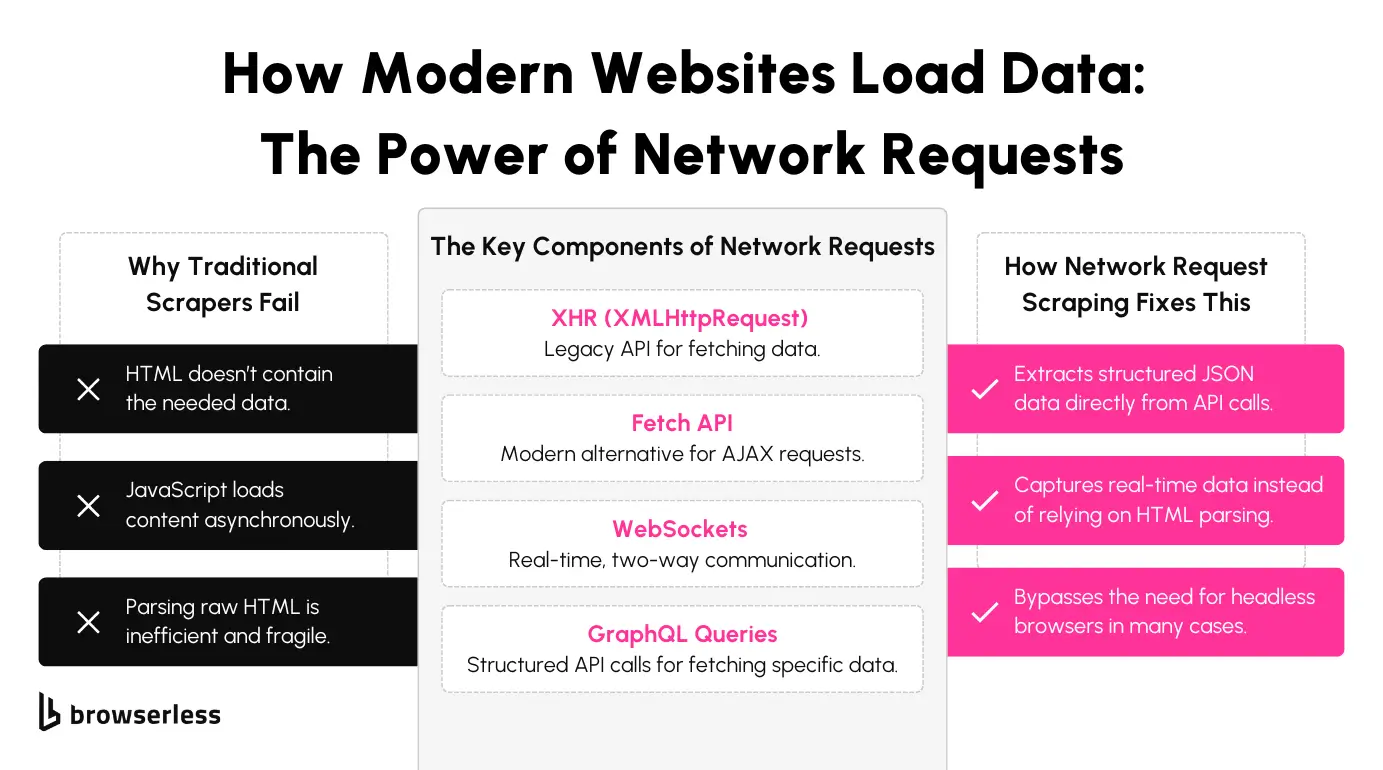
Today’s web applications rely heavily on network requests to deliver content dynamically. Technologies like XHR (XMLHttpRequest), the Fetch API, WebSockets, and GraphQL queries enable websites to load data asynchronously, allowing pages to update without a full refresh.
Instead of embedding all content in the initial HTML response, many applications retrieve data on demand through these network requests. For scrapers, this shift changes how data is accessed. Information that was once readily available in the HTML source is often fetched separately, making it necessary to monitor network activity to capture the data as it loads.
Why Traditional Scraping Techniques Struggle with SPAs
Single-page applications (SPAs) depend on API calls to populate content dynamically. This design improves user experience but introduces challenges for traditional scraping methods.
HTML parsing becomes unreliable because the initial HTML often lacks the needed data. SPAs typically load information after the page renders, meaning the DOM might not contain certain elements unless JavaScript executes them. Scraping the static source won’t capture this content.
Asynchronous loading adds complexity. Data is frequently fetched in response to user interactions or specific page triggers. Scrapers that don’t account for these delayed requests may capture incomplete or outdated information.
Frequent changes to frontend code and API endpoints increase maintenance overhead. SPAs are updated regularly, which can cause previously working selectors or API routes to break. Scrapers tied to fragile DOM structures or hardcoded endpoints risk failing when the site changes.
Scraping SPAs with BrowserQL
BrowserQL provides a direct way to monitor and capture network requests as they occur in the browser. Instead of parsing rendered HTML, you can intercept the exact API calls a site uses to fetch data.
BQL supports filtering requests by URL patterns, request types, and HTTP methods, making it easier to focus on relevant traffic. This allows you to extract details like headers, authentication tokens, and request payloads without relying on guesswork or fragile DOM selectors.
Here’s an example of how BQL captures outgoing network requests during page navigation:
mutation capture_requests {
goto(url: "https://example.com", waitUntil: networkIdle) {
status
}
requests(pattern: "**/api/**", types: [xhr, fetch], methods: [GET, POST]) {
url
method
headers
postData
}
}
This query directs the browser to the target URL, waits until network activity subsides, and collects requests matching the "/api/" pattern. It filters by request types (xhr and fetch) and methods (GET and POST). When applicable, the results include the request URL, HTTP method, headers, and body data.
Capturing network requests at this level provides structured data directly from the source, reducing dependency on rendered HTML and improving data extraction reliability.
Request Query vs. Response Query: What’s the Difference?

Scraping dynamic websites often requires monitoring both outgoing requests and incoming responses. BrowserQL offers two distinct query types: Request Query and Response Query. Each is designed to capture different parts of the network communication process. Understanding their differences helps select the right approach for extracting the necessary data.
Request Query: Monitoring Outgoing Requests
A Request Query captures details about the network requests that the browser sends to the server, including information about the request URLs, methods, headers, and payloads. Monitoring outgoing requests is useful when you need to identify which API endpoints a website relies on or when you want to inspect how data is being sent to back-end services. It also provides insight into authentication mechanisms by exposing token or session identifier headers.
Extracting request payloads can be valuable for debugging or reverse engineering how a web application communicates with its server. Observing the exact data sent allows you to replicate API calls without simulating complex front-end interactions. This helps streamline data extraction by targeting direct API endpoints rather than dealing with the rendered page content.
Limitations
While Request Queries provide extensive details about what the browser sends, they do not include the server’s response data. If you need the actual content returned from the API, such as JSON payloads or HTML fragments, you will need to use a Response Query instead.
Some websites also implement request obfuscation or encryption, making it harder to interpret the payload without further analysis. In these cases, simply capturing the request details may not be enough to retrieve the desired data.
Filtering Requests with BrowserQL
BQL simplifies capturing outgoing requests by allowing you to filter them based on URL patterns, request types, or HTTP methods. This level of control helps you focus on relevant traffic without being overwhelmed by every request the browser makes.
You can extract headers and authentication tokens directly through BQL without additional proxy configurations or external tools. Here’s an example of how you can use BQL to capture and filter outgoing requests:
mutation capture_outgoing_requests {
goto(url: "https://example.com", waitUntil: networkIdle) {
status
}
request(pattern: "**/api/**", types: [xhr, fetch], methods: [GET, POST]) {
url
method
headers
postData
}
}
In this example, the query navigates to the specified URL and captures outgoing requests matching the "**/api/**" pattern. It filters for xhr, fetches request types and focuses on GET and POST methods. The result includes the request URL, method, headers, and payload data.
This approach enables you to isolate the relevant network activity, quickly identify the API endpoints, and request details needed for your scraping workflow.
Response Query: Capturing Incoming Data
A Response Query retrieves the data sent back to the browser after a network request is made. This allows you to capture the content delivered by servers, including JSON payloads, HTML fragments, and other response data.
Monitoring incoming responses is especially useful for extracting structured data directly from API calls without relying on parsing the rendered HTML. Exposing cookies and headers returned by the server also provides insight into how websites manage authentication.
Response Queries are valuable for performance monitoring, providing visibility into request and response times. By capturing response data, you can assess how quickly a server delivers content and analyze the payload for debugging or data extraction. This direct access to server responses is particularly helpful when dealing with single-page applications or sites that load most of their data through JavaScript-driven API calls.
Limitations
While Response Queries provide access to a wide range of response data, they cannot decrypt encrypted content. You'll need additional methods to interpret the data if a website uses encrypted payloads or proprietary encoding.
Some APIs also implement strict authentication measures that are difficult to bypass without valid credentials, limiting what can be captured through standard response monitoring.
Capturing Responses with BrowserQL
BQL simplifies capturing incoming response data by giving you direct access to response bodies in various formats, including JSON, HTML, and plain text. It can also handle binary data, such as images or files, by converting it to a Base64-encoded string. This functionality allows you to extract meaningful data without creating complex proxies or additional tools.
Here’s how BQL captures response data with filtering options:
mutation capture_incoming_responses {
goto(url: "https://example.com", waitUntil: networkIdle) {
status
}
response(pattern: "**/api/**", types: [xhr, fetch], methods: [GET, POST]) {
url
status
headers
body
}
}
In this query, the browser navigates to the target URL and waits until network activity settles. It captures incoming responses that match the "**/api/**" pattern, focusing on xhr and fetch requests with GET and POST methods. The response data includes the request URL, HTTP status code, headers, and the response body. If the response is textual (e.g., JSON or HTML), the body is returned as a string; if it’s binary (like an image), it’s encoded in Base64. This level of access enables
What You Can and Can’t Do With Network Scraping

Network scraping directly extracts data by monitoring the requests and responses exchanged between the browser and servers. While this method is often effective, its capabilities are clearly defined. Understanding strengths and limitations is important when deciding how to incorporate them into your scraping workflow.
What You Can Do
Network scraping lets you extract structured data directly from API calls, making the process cleaner and more efficient than parsing rendered HTML. Instead of dealing with messy DOM structures and potential changes to front-end code, you can target the underlying data sources that websites use to populate their content. This results in more consistent and maintainable extraction methods, especially for applications built on dynamic frameworks.
Monitoring network traffic lets you identify authentication mechanisms and capture tokens embedded in request headers. This insight can be valuable for replicating session-based requests or accessing data behind login walls, provided you have the necessary credentials.
Focusing on the network layer can reduce reliance on full-page rendering, improving the speed and performance of your scraping process. Without the overhead of rendering, you can target API endpoints directly, which is often faster and less resource-intensive.
What You Can’t Do
Despite its advantages, network scraping has its limitations. It cannot bypass encrypted or obfuscated requests without additional decryption methods. Some websites use advanced techniques to hide payloads or encrypt their communications, which prevents direct extraction through standard network monitoring. Without proper decryption or reverse engineering, this data remains inaccessible.
Authentication barriers can also pose challenges. Many APIs require valid session tokens or advanced authentication flows that cannot be easily bypassed. Even when requests are visible, sending valid credentials without proper authorization is often impossible.
Some responses are compressed or encoded in proprietary formats, requiring extra processing before the data becomes usable. Network scraping cannot fully replace browser-based interactions either; certain JavaScript-heavy applications still require a rendered environment to trigger necessary requests.
Where BQL Fits In
BQL streamlines network scraping by providing tools to monitor requests and responses without manually managing raw network traffic. It integrates with traditional headless browsers when needed, allowing you to combine both approaches for complex scraping tasks. With BQL, you can capture structured data efficiently, filter network events by patterns, and extract response bodies without relying on extensive browser automation setups.
Here BQL can capture both outgoing requests and incoming responses in a single query:
mutation capture_network_traffic {
goto(url: "https://example.com", waitUntil: networkIdle) {
status
}
request(url: "**/api/**", type: [xhr, fetch]) {
url
method
headers {
name
value
}
}
response(url: "**/api/**", type: [xhr, fetch]) {
url
status
headers {
name
value
}
body
}
}
This query navigates to the specified URL, waits for the page to finish loading, and captures both the outgoing requests and incoming responses related to API calls. You can extract request headers, payloads, response bodies, and HTTP status codes, giving you full visibility into the data flow between the client and server. By combining request and response tracking, BQL helps you gather the necessary information without the complexity of setting up lower-level network monitoring tools.
Conclusion
Scraping network requests enables faster and cleaner data extraction than traditional methods, especially when combined with headless browsing for added flexibility.
BQL streamlines this process by allowing you to capture requests and responses directly, helping you extract data more efficiently while reducing complexity. Ready to improve your scraping workflow? Sign up for a Browserless account and start using BQL to streamline your data extraction today.
FAQ
What is the difference between request and response queries in BrowserQL?
Request queries capture the details of outgoing network requests, such as URLs, methods, headers, and payloads. Response queries, on the other hand, retrieve the data returned by the server, including JSON, HTML, and binary files, allowing you to access the actual content being loaded by the browser.
Can network request scraping replace traditional HTML scraping?
Network request scraping provides faster and more reliable access to structured data, especially for API-driven sites. However, it may not capture content rendered entirely through client-side JavaScript interactions, making it best used alongside traditional scraping methods for complete coverage.
Is it possible to capture data behind authentication barriers using BQL?
BQL can capture authentication tokens and cookies from outgoing and incoming requests, allowing you to replicate authenticated API calls. However, accessing protected data requires valid credentials and cannot bypass secure authentication mechanisms.
How does BQL handle binary data in responses?
BQL converts binary response data, such as images or files, into Base64-encoded strings. This enables you to capture and process non-textual data while working within the JSON-based GraphQL structure BQL uses.