Web scraping often becomes complicated when dealing with complex page structures, nested elements, and dynamic content. Managing these challenges typically requires a significant amount of code, which can quickly become difficult to maintain.
Our new mapping feature is designed to make data extraction faster, cleaner, and easier to manage. This article explores how our mapping feature works, why it benefits developers, and how you can integrate it into your projects.
Getting Started with Browserless Mapping
What is the Mapping Feature?
Using a declarative syntax, our mapping feature introduces a streamlined way to extract data from web pages. Instead of spending time writing loops, managing DOM traversals, or handling complex conditional logic, you simply define what you need with mapSelector. This command focuses on targeting elements directly, allowing you to specify the exact data points without the overhead of managing how the extraction occurs.
The result is faster development cycles and more readable code. With fewer lines to maintain, you spend less time troubleshooting and more time focusing on the data you’re collecting. Whether working solo or collaborating with a team, using mapSelector simplifies your scraping workflow, making it easier to scale projects or hand off code to others.
How It Works
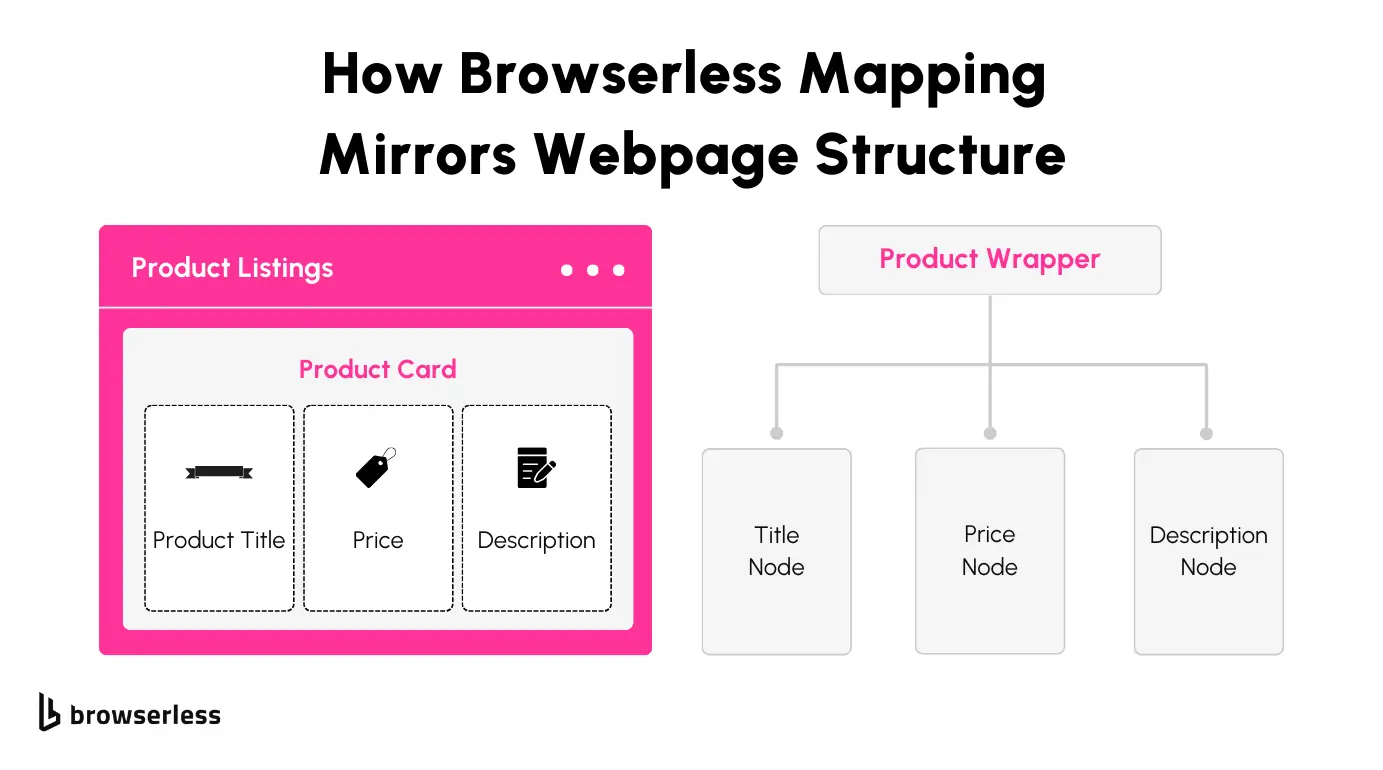
The mapSelector command reflects the webpage's structure, making selecting nested elements intuitively. When a site has complex layouts with multiple layers of elements, like product cards containing titles, prices, and descriptions, mapSelector lets you define these relationships functionally. Instead of manually traversing the DOM, you can map selectors in a hierarchy that mirrors how elements are structured in the HTML.
You can extract multiple data points, such as product names, pricing details, and links, without writing repetitive loops or additional extraction logic with one query. This speeds up the scraping process and reduces the chance of errors, especially when dealing with large pages or dynamic content.
Here’s an example of using the mapping feature to extract product information from an e-commerce site. The query navigates to the page, waits for the content to load, and collects details like product titles, prices, and descriptions.
mutation ScrapeProducts {
# Optimize bandwidth by rejecting unnecessary assets
reject(type: [image, media, font, stylesheet]) {
enabled
time
}
# Navigate to the e-commerce products page
goto(
url: "https://example-ecommerce.com/products"
waitUntil: firstContentfulPaint
) {
status
}
# Extract structured product data
mapProducts: mapSelector(selector: ".product-card") {
title: mapSelector(selector: ".product-title", wait: true) {
text: innerText
}
price: mapSelector(selector: ".product-price", wait: true) {
amount: innerText
}
description: mapSelector(selector: ".product-description", wait: true) {
text: innerText
}
link: mapSelector(selector: ".product-title > a", wait: true) {
url: attribute(name: "href") {
value
}
}
}
}
- **Navigating to the Page:
- **The
gotoblock tells Browserless to open the target URL and wait until the main content is fully rendered. This ensures that dynamic content loaded via JavaScript is available before extraction begins.
- **The
- **Mapping Product Cards:
- **The
mapSelector(selector: ".product-card")targets all product cards on the page. Each product card becomes a parent container for nested selectors, making it easy to extract multiple fields in a structured way.
- **The
- Extracting Nested Elements:**Title:** Pulls the product name from elements with the
.product-titleclass.Price: Retrieves the price from the.product-priceselector.**Description:** Captures the product description for additional context. - Title: Pulls the product name from elements with the
.product-titleclass. - Price: Retrieves the price from the
.product-priceselector. - Description: Captures the product description for additional context.
This way, you can retrieve all relevant data in a single query by mapping elements. There’s no need for additional code to handle iteration or complex DOM traversal. Everything is structured, consistent, and easier to debug. The mapping feature emphasizes providing you with direct access to the data you need while minimizing overhead and potential points of failure.
Why You Will Love the Mapping Feature
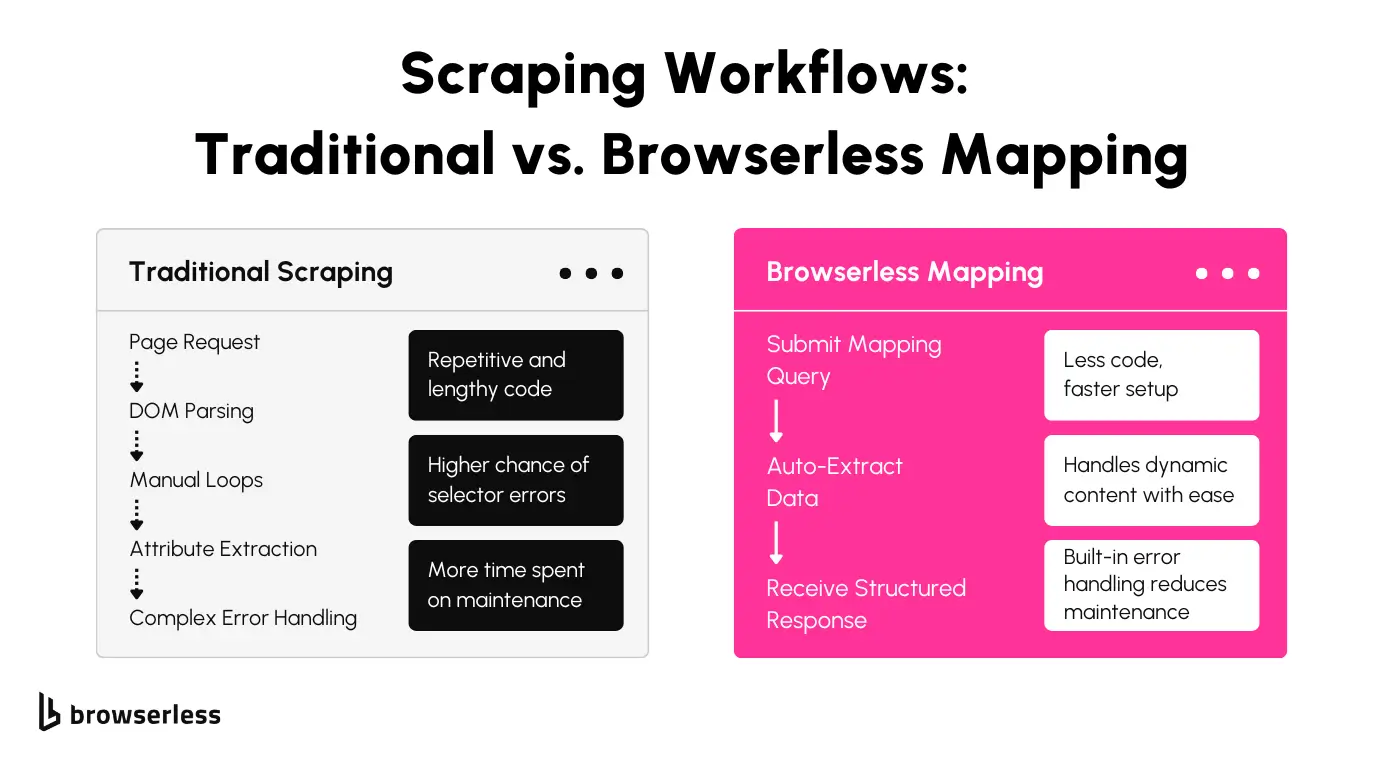
Cleaner, More Readable Code
Writing web scraping scripts can quickly become complicated when you rely on manual loops and nested selectors. The Browserless mapping feature changes that by letting you define clear, structured queries that are easy to read and maintain.
With fewer lines of code, your scripts become more understandable for you and anyone else working on the project. This makes collaboration smoother and revisiting old code far less frustrating.
Scoped Selectors That Make Sense
When dealing with complex pages, it’s common to encounter elements that share the same classes or IDs in different sections. The mapSelector feature addresses this by working within the context of its parent selector.
This scoped approach ensures you extract the right data without accidentally removing unrelated information from other page parts. It’s especially useful for pages with repeating sections or similar elements.
Built-in Attribute and Text Extraction
Extracting element attributes like href or title often requires extra parsing steps in traditional scraping methods. With mapSelector, you can grab these attributes directly without additional code.
The feature also makes pulling inner text straightforward, allowing you to focus on collecting the necessary information rather than writing boilerplate extraction logic. This improves efficiency while keeping your scripts clean.
Handles Dynamic Content and Errors Gracefully
Modern websites often load content asynchronously using JavaScript, which can complicate data extraction. The mapping feature includes built-in support for handling dynamic content through the waitUntil parameter, ensuring your script waits for the right elements before trying to extract them. If a selector isn’t found, your scraping process continues without breaking, allowing you to handle missing elements without dealing with complicated error-handling logic.
The example below shows how to use the mapping feature to extract product information from a dynamically loaded e-commerce page. The query waits for content to load before pulling product titles, prices, and links.
mutation ScrapeDynamicProducts {
# Optimize bandwidth by excluding non-essential assets
reject(type: [image, media, font, stylesheet]) {
enabled
time
}
# Load the e-commerce page and wait for rendering
goto(
url: "https://example-ecommerce.com/products"
waitUntil: firstContentfulPaint
) {
status
}
# Map over product cards and extract details
mapProducts: mapSelector(selector: ".product-card") {
title: mapSelector(selector: ".product-title", wait: true) {
text: innerText
}
price: mapSelector(selector: ".product-price", wait: true) {
amount: innerText
}
link: mapSelector(selector: ".product-title a", wait: true) {
url: attribute(name: "href") {
value
}
}
}
}
- Page Load: The
gotocommand loads the target URL and waits for the main content to finish rendering. This prevents the script from attempting to extract elements that have yet to load. - **Product Mapping:
- **The
mapSelector(selector: ".product-card")identifies each product card on the page. Within each card, the nested selectors pull specific information.
- **The
- Data Extraction Details:Title: Extracts the inner text from elements with the
.product-titleclass.Price: Captures the text value representing the product’s price.Link: Directly retrieves thehrefattribute from the anchor tag inside the title. - Title: Extracts the inner text from elements with the
.product-titleclass. - Price: Captures the text value representing the product’s price.
- Link: Directly retrieves the
hrefattribute from the anchor tag inside the title.
Using this structure lets you extract all relevant product details in a single, organized query. You avoid common issues with dynamic content and redundant data extraction by waiting for the page to load and scoping selectors to their parent elements. The result is a more reliable, efficient scraping process that requires less manual intervention.
Use Cases & Best Practices
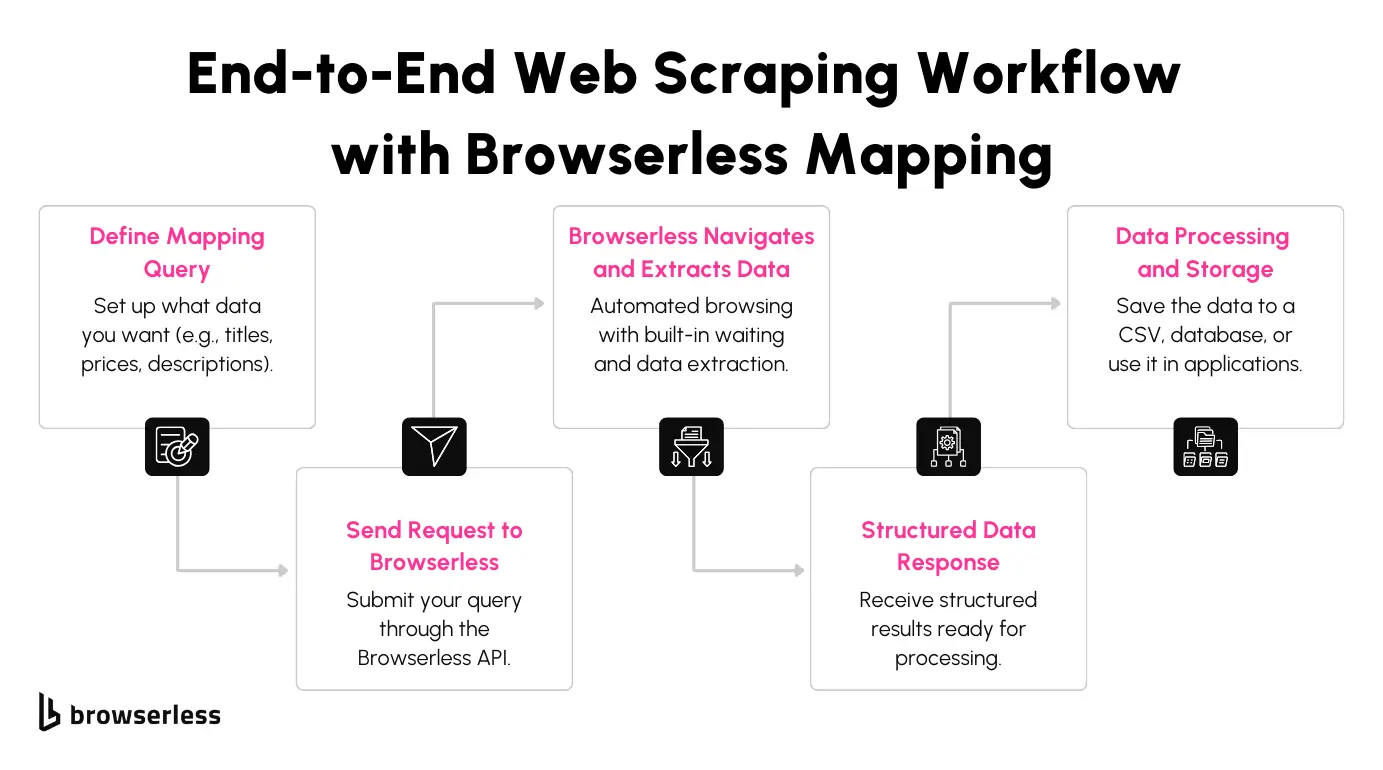
Scraping E-commerce Data Without the Hassle
Extracting product listings from e-commerce websites can be tedious, especially when dealing with complex page structures. The Browserless mapping feature simplifies this by allowing you to pull prices, descriptions, links, and other product details in fewer lines of code.
Using nested mapSelector blocks, you can capture all relevant information from multiple page sections in a single query. This saves time and reduces the chances of errors when working with large volumes of data.
Dealing with Dynamic Pages and Delayed Content
Many modern websites load content asynchronously, which can complicate data extraction. The waitUntil parameter helps address this issue by pausing your script until key elements are fully loaded.
This feature ensures you don’t miss content generated by JavaScript or lazy-loading mechanisms. It also allows you to extract complete datasets from dynamic pages without adding extra scripts or timing workarounds.
You can also add click or scroll commands to interact with the page and load new elements.
Tips to Keep Your Scraping Efficient
Maintaining efficiency in your scraping projects is crucial for scalability and reliability. Using reusable mapSelector blocks across different pages helps keep your code consistent and reduces duplication. Validating your selectors before running large-scale extractions prevents unnecessary API calls and improves performance. Monitoring response statuses during scraping also helps you catch issues early, ensuring smoother data collection across long-running tasks.
Let's tie this together in the following example, which shows you how to extract product titles, prices, descriptions, and links from an e-commerce test site. The query is structured to handle dynamic content and maintain session persistence, making it suitable for scraping multiple pages in a single run.
mutation ScrapeEcommerceSite {
# Optimize bandwidth by rejecting images, media, fonts, and stylesheets
reject(type: [image, media, font, stylesheet]) {
enabled
time
}
# Load the product listings page and wait for full network activity
goto(url: "https://example-ecommerce.com/products", waitUntil: networkIdle) {
status
}
# Extract product details from the first page
mapProducts: mapSelector(selector: ".product-card") {
title: mapSelector(selector: ".product-title", wait: true) {
text: innerText
}
price: mapSelector(selector: ".product-price", wait: true) {
amount: innerText
}
description: mapSelector(selector: ".product-description", wait: true) {
text: innerText
}
link: mapSelector(selector: ".product-title a", wait: true) {
url: attribute(name: "href") {
value
}
}
}
# Click on "Next" to navigate to the next page and wait for the new content
nextPage: click(selector: ".pagination-next", wait: true) {
time
}
# Extract product details from the second page
moreProducts: mapSelector(selector: ".product-card", wait: true) {
title: mapSelector(selector: ".product-title") {
text: innerText
}
price: mapSelector(selector: ".product-price") {
amount: innerText
}
}
}
What’s Happening in This Query:
- Page Navigation: The
gotoblock opens the product listings page and waits until the network is idle. This ensures that all dynamically loaded elements are available for extraction. - Product Mapping: The
mapSelector(selector: ".product-card")targets individual product cards. Nested selectors within each card extract specific data points:Title: Retrieves the inner text from.product-title.Price: Captures the text representing the product price.Description: Pulls the inner text for product descriptions.Link: Extracts thehrefattribute for product links. - Title: Retrieves the inner text from
.product-title. - Price: Captures the text representing the product price.
- Description: Pulls the inner text for product descriptions.
- Link: Extracts the
hrefattribute for product links. - Handling Multi-Page Scraping: The
click(selector: ".pagination-next")simulates clicking the "Next" button, allowing you to scrape additional pages. Combined with session persistence, this ensures the scraper maintains its state while collecting data across multiple pages.
Conclusion
Our mapping feature is built to simplify web scraping while giving developers better control over data extraction. It reduces redundant code, handles dynamic content without additional workarounds, and improves script readability. Whether you’re extracting product listings from e-commerce platforms or collecting information from content-heavy pages, this feature makes the process more efficient and easier to maintain. If you want to streamline your scraping workflows, the mapping feature will help you save time and reduce complexity. Try it out and experience how it simplifies your data extraction tasks.
FAQs
What is Browserless’s mapping feature, and how does it help developers?
Browserless’s mapping feature provides a cleaner, declarative syntax for web scraping. Instead of writing complex loops and extensive code to extract data, you define what you need using mapSelector. This reduces development time, improves code readability, and makes it easier to maintain scraping scripts, especially when working with complex page layouts.
How does Browserless handle scraping dynamic websites?
Browserless includes built-in support for dynamic content through features like waitUntil. This allows your scraper to pause until the necessary elements are fully loaded, ensuring data generated by JavaScript or lazy-loading techniques is captured. This eliminates the need for extra timing scripts or manual adjustments to handle delayed content.
Can I extract multiple data points at once with Browserless mapping?
Yes. The mapping feature supports nested mapSelector blocks, allowing you to extract data points such as product titles, prices, descriptions, and links in a single query. This approach minimizes code duplication and streamlines the extraction process, making your scripts shorter and more efficient.
Is Browserless mapping suitable for large-scale scraping projects?
It is. Our mapping feature is designed to handle large-scale scraping tasks efficiently. With features like session persistence, error handling, and support for multi-page extraction, it can process high volumes of data without unnecessary complexity. This makes it a strong choice for projects requiring consistent and reliable data collection across many pages or websites.